XML
Autres exemples d'utilisation de XML
Le dictionnaire JMdict
Choix typographiques
SAX, XSLT, DOM, XPath
XSLT
DOM
Quelques problèmes ponctuels
LaTeX
Omega
Remarques et critiques
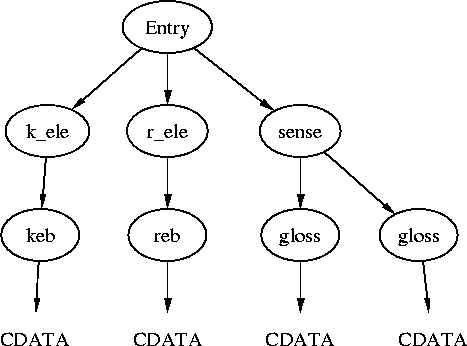
Un fichier XML est un fichier texte, sous un format particulier. Il est constitué de différents champs, délimités par des balises qui ressemblent au HTML. La principale différence avec de HTML (ou le SGML) c'est qu'à toute balise ouvrantde doit correspondre une balise fermante, même pour les champs vides (mais on utilisera l'abréviation <hr/> au lieu de <hr></hr> pour de tels champs vides).
Voici un exemple de fichier XML :
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE quotations>
<quotations>
<quote author="Alfred Hitchcock">
Television has brought back murder into the home -- where it belongs.
</quote>
<quote author="Geoffrey James" reference="The Tao of Programming">
<line>A well-used door needs no oil on its hinges.</line>
<line>A swift-flowing steam does not grow stagnant.</line>
<line>Neither sound nor thoughts can travel through a vacuum.</line>
<line>Software rots if not used.</line>
<line/>
<line>These are great mysteries.</line>
</quote>
</quotations>La première ligne indique qu'il s'agit d'un fichier XML et en donne le codage.
La seconde ligne est facultative : elle dit de quel type de fichier il s'agit ; ici, il y aura donc un fichier quotation.dtd (un DTD) ou quotation.xsd (un schéma) qui décrira ce type de fichier.
On a ensuite des balises ouvrantes ou fermantes, qui délimitent des données diverses. On remarquera que quand une balise est vide, on l'écrit <line/> plutôt que <line></line>.
Certaines balises, ici <quote>, prennent des arguments (on parle plutôt d'attributs).
On trouve aussi parfois des entités, i.e., des macros, par exemple pour des caractères que l'on ne pourrait pas taper sinon (comme < ou &, qui se saisissent respectivement > et &) ou pour du texte qui revient souvent.
L'intérêt du XML est que jusqu'à présent, à chaque fois qu'un programme devait lire des données dans un fichier texte, ces données étaient dans un format particulier (qui variait d'un programme à l'autre), il fallait donc écrire une fonction qui lise ce format particulier, et tout était à refaire dès que le format changeait. Désormais, pour lire un fichier XML, il suffit d'utiliser les fonctions d'une bibliothèque XML, indépendemment du programme.
Voici quelques exemples d'utilisation de XML. S'ils ne vous intéressent pas, ou si vous avez déjà compris qu'XML pouvait être utile, passez directement à la suite.
Les pages Web ne sont plus écrites en HTML (qui n'est pas du XML), en XHTML (c'est pareil, sauf qu'en HTML on n'est pas obligé de mettre des balises fermantes, alors qu'en XHTML, si : par exemple, le contenu d'un paragraphe sera délimité par <p> et </p>) ou en WML (pour le Wap).
On peut coder d'autres types de documents en XML : par exemple, DocBook (ou son concurrent TEI), permet de coder des livres, avec chapitres, sections, sous-sections, bibliographies, index, etc. Il y a aussi plein d'outils pour transformer un fichier DocBook en HTML, texte, LaTeX, PostScript ou PDF (d'ailleurs, ces outils sont paramétrables en XML). Comme DocBook est prévu pour des tous types de documents, il est très général, très long et très complexe.
À l'intérieur d'un document DocBook, on peut vouloir mettre des choses un peu particulières, comme des formules mathématiques ou chimiques : on peut utiliser localement des DTD (ou des schémas) pour coder de telles choses, comme MathML ou CML.
http://www.webeq.com/mathml/ http://www.zvon.org/HowTo/Output/index.html http://www.xml-cml.org/information/position.html http://www.zvon.org/xxl/CML1.0/Output/
Un document DocBook peut même contenir des illustrations, toujours en XML (SVG : Scalable Vector Graphics). Ces animations peuvent même être animées ou interactives.
Une base de données stocke ses données dans des tableaux : on peut donc facilement la convertir en XML. C'est utile, par exemple pour copier l'intégralité d'une base de données dans un autre logiciel (mais c'est bien évidemment à proscrire comme format de stockage à l'intérieur d'une base de données, car le XML n'est pas du tout conçu pour permettre une recherche rapide d'information).
Le dictionnaire que nous utiliserons rentre dans cette catégorie.
Un service Web, c'est exactement comme une page Web avec un formulaire (on remplit le formulaire, on l'envoie, et on reçoit une réponse, par exemple, on donne l'ISBN d'un livre à amazon.co.uk, et il nous donne le titre, l'auteur et le prix), à ceci près qu'il n'est pas utilisé par un être humain, mais par des machines : il n'y aura donc pas de HTML génant tout autour.
La description de ces services Web se fait en XML (WSDL : Web Service Description Language) : on précise qu'il y a telle fonction, à tel URL, on précise quel sont ses arguments et leur type (éventuellement des types complexes) et ce qu'elle renvoie.
L'appel d'un service Web et la réponse sont des fichiers XML (SOAP), qui contiennent le nom du service et la liste des arguments.
http://www.oreillynet.com/pub/a/webservices/2002/02/12/webservicefaqs.html http://linuxfr.org/2002/04/15/7943,0,1,1,0.php3 http://www.samag.com/documents/s=1784/sam05060001/tpj05060001.htm http://www.google.com/apis/ http://www.xmethods.net/
On peut décrire des interfaces utilisateur (dire qu'il y a une fenêtre avec tel bouton à tel endroit, un menu à tel tel endroit, etc.) en XML. C'est ce qu'utilise le navigateur Mozilla.
http://www.xulplanet.com/tutorials/xultu/
Le dictionnaire Japonais -> Anglais/Français/Allemand est au format XML. C'est une succession de blocs <entry>, chacun contenant la ou les écritures du mot, dans un(des) bloc(s) <k_ele>, puis la ou les prononciations du mot, dans un(des) bloc(s) <r_ele>, puis la ou les familles de traduction, dans un(des) bloc(s) <sense>. (Le dessin suivant aurait pu être fait avec GraphViz::XML.)
<entry>
<k_ele>
<keb>車</keb>
</k_ele>
<r_ele>
<reb>くるま</reb>
</r_ele>
<sense>
<gloss>car</gloss>
<gloss>vehicle</gloss>
<gloss>wheel</gloss>
</sense>
</entry>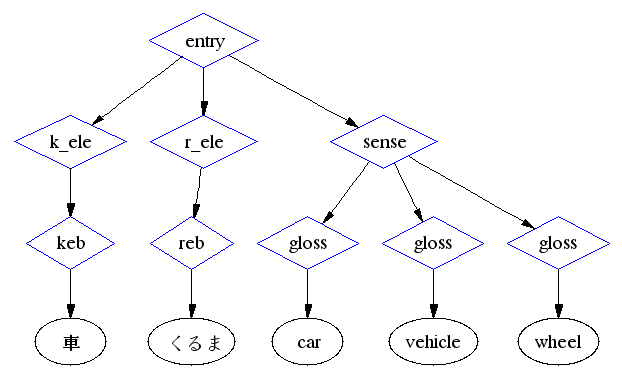
En fait, cet exemple est simplifié. Voici la vraie entrée.
<entry>
<ent_seq>1323080</ent_seq>
<k_ele>
<keb>車</keb>
<ke_pri>ichi1</ke_pri>
<ke_pri>jdd1</ke_pri>
</k_ele>
<r_ele>
<reb>くるま</reb>
<re_pri>ichi1</re_pri>
<re_pri>jdd1</re_pri>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>car</gloss>
<gloss>vehicle</gloss>
<gloss>wheel</gloss>
<gloss g_lang="de">Wagen</gloss>
<gloss g_lang="de">-Rad</gloss>
</sense>
<sense>
<gloss g_lang="fr">voiture</gloss>
<gloss g_lang="fr">véhicule</gloss>
</sense>
</entry>Le bloc <ent_seq> est simplement un numéro identifiant de manière unique l'entrée.
Les blocs <gram> indiquent la (ou les) natures grammaticales du mot. L'entité &n; est simplement une abréviation pour « nom commun », comme précisé dans l'en-tête du fichier.
<!ENTITY n "noun (common) (futsuumeishi)">
Les blocs <gloss>, indiquant les traductions, peuvent avoir un attribut g_lang indiquant la langue de la traduction, comme anglais (en), allemand (de) ou français (fr).
Les blocs <ke_pri> et <re_pri> indiquent la priorité de la lecture ou de l'écriture. ichi1 désigne les 10000 mots les plus courrants, jdd1 désigne les mots de JDDict (un dictionnaire Japonais-Allemand d'à peu près 10000 mots), gai1 désigne les mots d'origine occidentale les plus courrants (à peu près 5000 mots)
Les différentes écritures/prononciations n'ont pas nécessairement la même priorité.
<entry>
<ent_seq>1001620</ent_seq>
<k_ele>
<keb>お握り</keb>
<ke_pri>ichi1</ke_pri>
</k_ele>
<k_ele>
<keb>御握り</keb>
</k_ele>
<r_ele>
<reb>おにぎり</reb>
<re_pri>ichi1</re_pri>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>hand rolled sushi</gloss>
</sense>
</entry>
<entry>
<ent_seq>1151580</ent_seq>
<k_ele>
<keb>悪戯</keb>
<ke_pri>ichi1</ke_pri>
<ke_pri>jdd1</ke_pri>
</k_ele>
<r_ele>
<reb>いたずら</reb>
<re_pri>ichi1</re_pri>
<re_pri>jdd1</re_pri>
</r_ele>
<r_ele>
<reb>あくぎ</reb>
<re_pri>jdd1</re_pri>
</r_ele>
<sense>
<gram>&adj-na;</gram>
<gram>&n;</gram>
<gram>&vs;</gram>
<gloss>tease</gloss>
<gloss>prank</gloss>
<gloss>trick</gloss>
<gloss>practical joke</gloss>
<gloss>mischief</gloss>
<gloss g_lang="de">-Streich</gloss>
<gloss g_lang="de">-Unfug</gloss>
</sense>
<sense>
<gloss g_lang="fr">(an)(vs) frasque</gloss>
<gloss g_lang="fr">mauvaise blague</gloss>
<gloss g_lang="fr">sale tour</gloss>
</sense>
</entry>
Les bloc <gram> se trouvent à l'intérieur d'un bloc <sense>.
(Normalement, j'aurais dû donner un exemple avec des blocs <gram> dans deux blocs <sense> différents, mais ça n'arrive qu'une seule fois (entrée numéro 1580030) et les deux blocs <gram> contiennent exactement la même chose.)
Le bloc <ke_inf> donne des informations supplémentaires sur une écriture d'un mot. En particulier, &iK; (utilisation irrégulière des kanji), &io; (utilisation irrégulière des okurigana) &oK; (kanji obsolètes).
<entry>
<ent_seq>1005970</ent_seq>
<k_ele>
<keb>じゃん拳</keb>
</k_ele>
<k_ele>
<keb>両拳</keb>
<ke_inf>&iK;</ke_inf>
</k_ele>
<r_ele>
<reb>じゃんけん</reb>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>rock-scissors-paper game</gloss>
</sense>
</entry>De même, le bloc <re_inf> donne des informations supplémentaires sur la lecture. Par exemple &ateji; (?) &gikun; (?) &ik; (utilisation irrégulière des kana) &ok; (utilisation obsolète des kana) &rare; &uk; (mot généralement écrit en kana uniquement).
<entry>
<ent_seq>1161240</ent_seq>
<k_ele>
<keb>一箇年</keb>
<ke_pri>jdd1</ke_pri>
</k_ele>
<r_ele>
<reb>いっかねん</reb>
<re_inf>&ok;</re_inf>
<re_pri>jdd1</re_pri>
</r_ele>
<sense>
<gloss>one year</gloss>
<gloss g_lang="de">ein Jahr</gloss>
</sense>
<sense>
<gloss g_lang="fr">(ok) une année</gloss>
</sense>
</entry>
<entry>
<ent_seq>1163940</ent_seq>
<k_ele>
<keb>一寸</keb>
<ke_pri>ichi1</ke_pri>
</k_ele>
<k_ele>
<keb>鳥渡</keb>
<ke_pri>ichi1</ke_pri>
</k_ele>
<r_ele>
<reb>ちょっと</reb>
<re_inf>&ateji;</re_inf>
<re_pri>ichi1</re_pri>
</r_ele>
<sense>
<gram>&adv;</gram>
<gram>∫</gram>
<misc>&uk;</misc>
<gloss>just a minute</gloss>
<gloss>a short time</gloss>
<gloss>a while</gloss>
<gloss>just a little</gloss>
<gloss>somewhat</gloss>
<gloss>easily</gloss>
<gloss>readily</gloss>
<gloss>rather</gloss>
</sense>
</entry>
<entry>
<ent_seq>1277290</ent_seq>
<k_ele>
<keb>向日葵</keb>
</k_ele>
<r_ele>
<reb>ひまわり</reb>
<re_inf>&gikun;</re_inf>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>sunflower</gloss>
</sense>
</entry>Le bloc <dial> signale un mot appartenant à un dialecte particulier. Par exemple kyb (Kyoto-ben), osb (Osaka-ben), ksb (Kansai-ben), ktb (Kantou-ben), tsb (Tosa-ben).
<entry>
<ent_seq>1412930</ent_seq>
<k_ele>
<keb>大きに</keb>
</k_ele>
<r_ele>
<reb>おおきに</reb>
</r_ele>
<info>
<dial>kyb:</dial>
</info>
<sense>
<gram>&adv;</gram>
<gram>∫</gram>
<misc>&uk;</misc>
<gloss>thank you</gloss>
</sense>
</entry>Le bloc <lang> indique la langue d'origine pour les mots importés. Par exemple ai (aïnu), ar (arabe), de (allemand), el (grec), en (anglais), eo (espéranto), es (espagnol), fr (français), ko (koréen), lt (lithuanian), nl (néerlandais), no (norvégien), pt (portuguais), ru (russe), sanskr (sanskrit), zh (chinois).
<entry>
<ent_seq>1019420</ent_seq>
<r_ele>
<reb>アルバイト</reb>
<re_pri>ichi1</re_pri>
<re_pri>gai1</re_pri>
</r_ele>
<info>
<lang>de:</lang>
</info>
<sense>
<gram>&n;</gram>
<xref>パートタイム</xref>
<gloss>part-time job (esp. high school students) (de: Arbeit)</gloss>
</sense>
</entry>Le bloc <xref> (comme dans l'exemple ci-dessus) renvoie à des mots synonymes.
Le bloc <ant> (qui n'apparait qu'une seule fois dans tout le dictionnaire) indique des antonymes.
<entry>
<ent_seq>1348350</ent_seq>
<k_ele>
<keb>小人</keb>
<ke_pri>ichi1</ke_pri>
<ke_pri>jdd1</ke_pri>
</k_ele>
<r_ele>
<reb>こびと</reb>
<re_pri>jdd1</re_pri>
</r_ele>
<r_ele>
<reb>しょうにん</reb>
<re_pri>ichi1</re_pri>
</r_ele>
<r_ele>
<reb>しょうじん</reb>
</r_ele>
<r_ele>
<reb>こども</reb>
<re_inf>&rare;</re_inf>
</r_ele>
<sense>
<gram>&n;</gram>
<ant>大人</ant>
<gloss>child</gloss>
<gloss>small person</gloss>
</sense>
<sense>
<stagr>こびと</stagr>
<ant>巨人</ant>
<gloss>dwarf</gloss>
</sense>
<sense>
<stagr>しょうじん</stagr>
<ant>君子</ant>
<gloss>narrow-minded person</gloss>
<gloss>mean person</gloss>
<gloss g_lang="de">Zwerg</gloss>
<gloss g_lang="de">Liliputaner</gloss>
<gloss g_lang="de">Kind</gloss>
<gloss g_lang="de">Kinder</gloss>
</sense>
<sense>
<gloss g_lang="fr">(rare) enfant</gloss>
<gloss g_lang="fr">personne de petite taille</gloss>
</sense>
</entry>Le champ <field> indique le domaine auquel appartien un mot spécialisé, par exemple &gram; (grammaire), ∁ (informatique) &MA; (arts martiaux).
<entry>
<ent_seq>1163740</ent_seq>
<k_ele>
<keb>一人称</keb>
</k_ele>
<r_ele>
<reb>いちにんしょう</reb>
</r_ele>
<sense>
<gram>&n;</gram>
<field>&gram;</field>
<gloss>first person</gloss>
</sense>
</entry>Le bloc <misc> contient d'autres informations sur une traduction, par exemple &buddh; (terme bouddhique), &chn; (terme enfantin), &id; (idiomatique), &fam; (familier), &obsc; (obscène), &fem; (langage féminin), ♂ (langage masculin), &vulg; (vulgaire), &sl; (argot), &X; (insultant, vulgaire ou pornographique), &pol; (poli), &hum; (humble), &hon; (honorifique), &rare; (rare), &obs; (obsolète), &arch; (archaïque), &col; (idioatique), &uk; (généralement écrit avec uniquement des kana), &abbr; (abbréviation).
<entry>
<ent_seq>1000130</ent_seq>
<k_ele>
<keb>N響</keb>
</k_ele>
<r_ele>
<reb>エヌきょう</reb>
</r_ele>
<sense>
<misc>&abbr;</misc>
<gloss>NHK Symphony Orchestra</gloss>
</sense>
</entry>Le bloc <s_inf> (il n'y en a qu'une seule occurrence dans tout le dictionnaire) donne des informations supplémentaires sur une traduction.
<entry>
<ent_seq>1217980</ent_seq>
<k_ele>
<keb>願わくわ</keb>
</k_ele>
<r_ele>
<reb>ねがわくわ</reb>
</r_ele>
<sense>
<gloss>I pray (mis-spelling)</gloss>
<s_inf>Should be 願わくは/ねがわくは</s_inf>
</sense>
</entry>
Le bloc <re_restr> indique qu'un lecture n'est valable que pour certaines écritures.
<entry>
<ent_seq>1006960</ent_seq>
<k_ele>
<keb>そよ風</keb>
<ke_pri>ichi1</ke_pri>
<ke_pri>jdd1</ke_pri>
</k_ele>
<k_ele>
<keb>微風</keb>
</k_ele>
<r_ele>
<reb>そよかぜ</reb>
<re_pri>ichi1</re_pri>
<re_pri>jdd1</re_pri>
</r_ele>
<r_ele>
<reb>びふう</reb>
<re_restr>微風</re_restr>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>gentle breeze</gloss>
<gloss>soft wind</gloss>
<gloss>breath of air</gloss>
<gloss>zephyr</gloss>
<gloss g_lang="de">leichte Brise</gloss>
</sense>
<sense>
<gloss g_lang="fr">brise douce</gloss>
<gloss g_lang="fr">vent léger</gloss>
</sense>
</entry>Le bloc <stagk>, quand il est présent, indique que la traduction n'est valable que pour certaines écritures du mot. (On remarque, sur cet exemple, que les entrées françaises et allemandes sont mises n'importe où...)
<entry>
<ent_seq>1323250</ent_seq>
<k_ele>
<keb>車両</keb>
<ke_pri>ichi1</ke_pri>
<ke_pri>jdd1</ke_pri>
</k_ele>
<k_ele>
<keb>車輛</keb>
</k_ele>
<r_ele>
<reb>しゃりょう</reb>
<re_pri>ichi1</re_pri>
<re_pri>jdd1</re_pri>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>rolling stock</gloss>
<gloss>vehicles</gloss>
</sense>
<sense>
<stagk>車輛</stagk>
<gloss>number of cars (in a train)</gloss>
<gloss g_lang="de">Wagen</gloss>
<gloss g_lang="de">Fahrzeug</gloss>
</sense>
<sense>
<gloss g_lang="fr">matériel roulant (ferroviaire)</gloss>
<gloss g_lang="fr">véhicule</gloss>
</sense>
</entry>De même, le bloc <stagr> indique qu'une traduction n'est valable que pour certaines prononciations d'un mot.
<entry>
<ent_seq>1414950</ent_seq>
<k_ele>
<keb>大文字</keb>
<ke_pri>ichi1</ke_pri>
</k_ele>
<r_ele>
<reb>おおもじ</reb>
<re_pri>ichi1</re_pri>
</r_ele>
<r_ele>
<reb>だいもんじ</reb>
</r_ele>
<sense>
<gram>&n;</gram>
<gloss>upper case letters</gloss>
<gloss>large characters</gloss>
</sense>
<sense>
<stagr>だいもんじ</stagr>
<gloss>the (kanji) character "dai" meaning "big"</gloss>
</sense>
<sense>
<stagr>だいもんじ</stagr>
<gloss>huge character "dai" formed by fires lit on the side
of a mountain in Kyoto on 16 Aug each year</gloss>
</sense>
</entry>
La structure du dictionnaire est formalisée dans un DTD (c'est l'en-tête du fichier JMdict.xml).
ftp://ftp.cc.monash.edu.au/pub/nihongo/JMdict.dtd
Certaines choses ne sont pas expliquées dans le DTD, comme les abbréviations dans les blocs <lang> ou <dial> (d'ailleurs, ce devraient être des entités, comme les remarques grammaticales). Elles sont détaillées ici :
http://www.csse.monash.edu.au/~jwb/edict_doc.html
Voici quelques exemples de ce que l'on aimerait obtenir.
Une entrée simple :
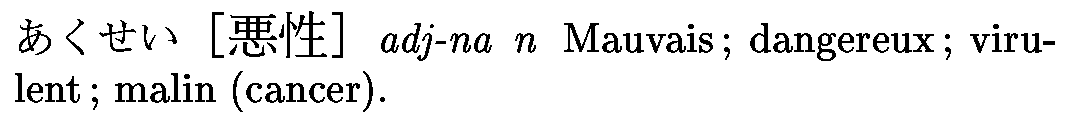
Une entrée plus complexe :

Une entrée avec plusieures prononciations :
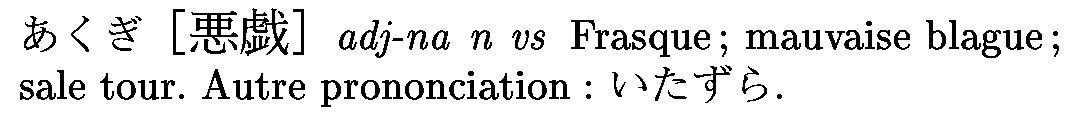
Une entrée avec plusieures écritures :
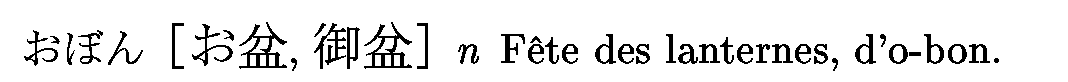
Une entrée avec des champs ke_inf.
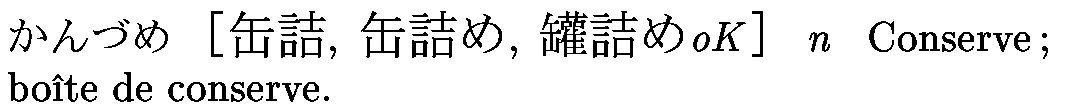
Deux entrées consécutives correspondant au même mot.
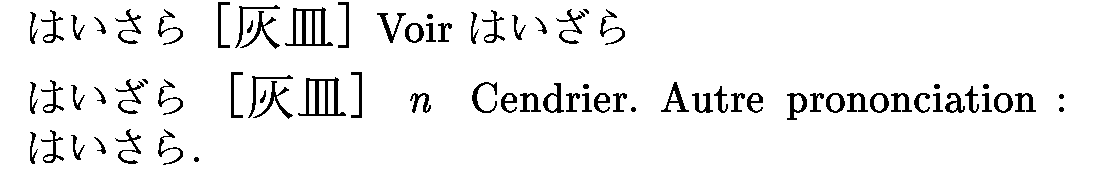
On aurait pu souligner les mots prioritaires, mais comme tous les mots du dictionnaire français ou allemand le sont, c'était très laid.
Un exemple d'entrée de JMdict éclatée en plusieures entrées différentes. Les différences peuvent être au niveau des écritures possibles,
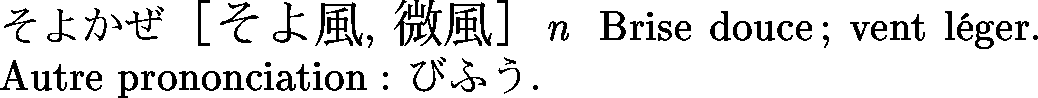
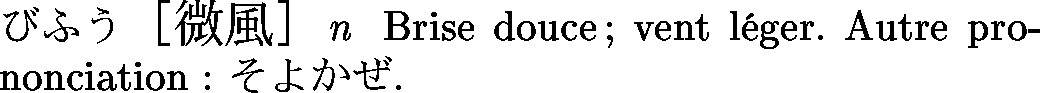
ou au niveau des traductions (balises stagk et stagr).


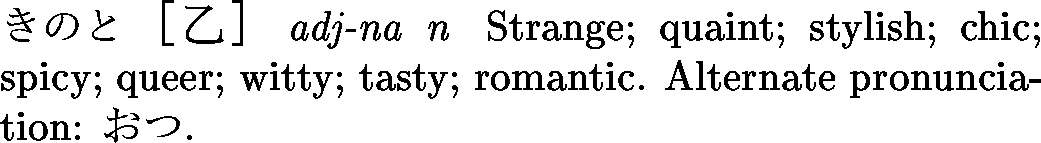
Changement de lettre

Dans le dictionnaire français, il n'y a pas de renvoi à une autre entrée, car (dans la version actuelle du dictionnaire), les balises <xref> sont dans des blocs <sense> vides. Par contre, dans le dictionnaire anglais, il y en a.

Dernier exemple :
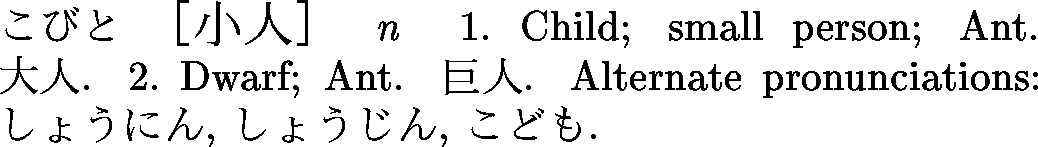
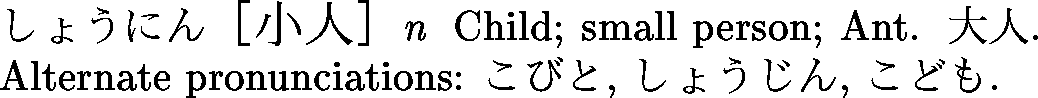
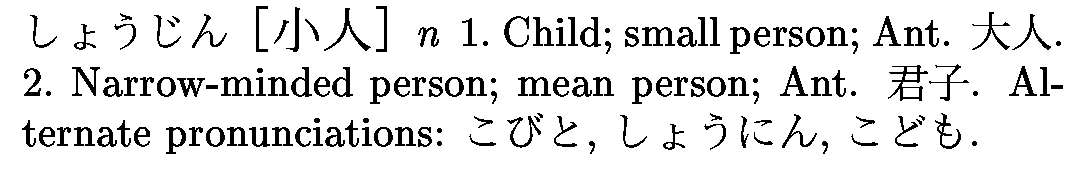

Il existe (je connais) trois standards pour manipuler des fichiers XML :
SAX (Simple API for XML) est l'interface la plus simple à expliquer, la plus rapide, la moins couteuse en mémoire, mais pas du tout la plus simple à utiliser. Elle consiste à découper le fichier en une succession d'évènements du genre « balise ouvrante <entry> », « balise fermante </sense> », « texte ». On programme en précisant ce qu'il faut faire à chaque évènement (c'est d'ailleurs ce que l'on appelle de la programmation évènementielle, que vous connaissez bien si vous avec déjà programmé des interfaces graphiques). Nous n'utiliserons pas SAX.
XSLT (eXtensible Stylesheet Language T???) est une autre interface simpliste, mais alors que SAX découpait le document en balises ouvrantes et fermantes, XSLT le découpe en blocs. Cela se rapproche toujours de la programmation évènementielle ; le programme ressemble à « si on rencontre tel bloc, faire ceci ». Les « programmes » XSLT sont en fait des documents XML.
DOM (Document Object Model) est une interface plus complexe, plus couteuse en mémoire, qui représente le fichier XML sous la forme d'un arbre, dans lequel on navique en donnant des ordres du genre « aller au premier noeud fils », « aller au noeud "frère suivant" », etc. Nous en aurons besoin pour lire les différentes entrées du dictionnaire : en particulier, XSLT ne serait pas pratique du tout pour traiter les blocs <re_restr>, <stagr> et <stagk>.
On rencontre aussi un autre sigle quand on manipule des documents XML : XPath. XPath est un moyen d'identifier un (ou plusieurs) noeud(s) dans un document XML. (C'est une sorte d'expression régulière pour fichiers XML, pour ceux qui savent ce que c'est.) Par exemple, pour désigner les blocs <dial> à l'intérieur des blocs <info> à l'intérieur des blocs <entry> dans le document, on dit /entry/info/dial. Autre exemple, pour désigner les blocs <dial> n'importe où dans le document, à n'importe quelle profondeur, on dit //dial. Dernier exemple, pour désigner les blocs <gloss> (à l'intérieur des blocs <sense> à l'intérieur des blocs <entry>) dont l'attribut g_lang vaut "fr", on dit /entry/sense/gloss[g_lang="fr"].
Nous avons vu que les trois dictionnaires japonais-allemand, japonais-anglais et japonais-français étaient mélangés dans un même fichier. Nous allons donc commencer par les extraire. Comme il s'agit d'une manipulation relativement simples, nous utiliserons XSLT.
http://www.zvon.org/xxl/XSLTutorial/Books/Output/contents.html http://www.datapower.com/XSLTMark/
Comme tout fichier XML, notre programme XSLT commencera par la ligne
<?xml version="1.0" encoding="utf-8"?>
On précise ensuite qu'il s'agit d'un document XSL. Contrairement au cas du dictionnaire, où on mettait le DTD tout entier, on se contente de définir un « espace de nommage » (xmlns signifie XML NameSpace) que l'on appelle xsl : toutes les balises qui commencent par xsl: correspondront à la feuille de style, les autres correspondront au DTD du document que l'on crée (toujours un dictionnaire, mais plus petit).
<xsl:stylesheet version = '1.0'
xmlns:xsl='http://www.w3.org/1999/XSL/Transform'>
...
</xsl:stylesheet>Nous allons remplir les pointillés. On commence par préciser quel type de fichier on veut créer (un fichier XML, HTML ou du texte) et quel est son codage.
<xsl:output method="xml" encoding="utf-8"/>
On commence par lui dire ce qu'il faut faire avec le bloc racine <JMdict>...</JMdict>. On lui dit simplement de remettre les balises <JMdict>...</JMdict> et de « faire ce qu'il faut » avec tous les blocs qu'il y a dans ce bloc racine. (Avec un langage de programmation classique, il aurait fallu faire une boucle sur tous les blocs <entry> contenus dans ce bloc racine : ici, on n'a pas besoin de boucle [mais il existe quand-même des boucles].)
<xsl:template match="/">
<JMdict>
<xsl:apply-templates select="*"/>
</JMdict>
</xsl:template>On précise ensuite ce qu'il faut faire des blocs <entry>. Deux deux choses l'une : soit il existe, dans cette entrée, un bloc <sense>, avec un bloc <gloss> qui a un attribut g_lang qui vaut 'fr', soit il n'y en a pas. S'il y en a, on va garder l'entrée (en enlevant tous les blocs <gloss> qui n'ont pas le bon atribut), s'il n'y en a pas, on oublie cette entrée.
Pour dire cela, on utilise un bloc conditionnel <xsl:if> et la syntaxe XPath introduite plus haut. Comme précedemment, on remarque que l'on précise les balises <entry>...</entry> et que l'on demande à l'ordinateur de « faire ce qu'il faut » avec les blocs plus intérieurs.
<xsl:template match="entry">
<xsl:if test="sense/gloss[@g_lang='fr']">
<entry>
<xsl:apply-templates select="*"/>
</entry>
</xsl:if>
</xsl:template>Il faut copier textuellement les blocs autres que <sense> ou <gloss>.
<!-- dans <entry> -->
<xsl:template match="ent_seq|k_ele|r_ele|info">
<xsl:copy-of select="."/>
</xsl:template>
<!-- dans <sense> -->
<xsl:template match="stagk|stagr|gram|xref|ant|field|misc|example|s_inf">
<xsl:copy-of select="."/>
</xsl:template>On précise enfin ce qu'il faut faire des blocs <sense>
<xsl:template match="sense">
<sense>
<xsl:apply-templates select="*"/>
</sense>
</xsl:template>et gloss.
<xsl:template match="gloss[@g_lang='fr']">
<xsl:copy-of select="."/>
</xsl:template>
<xsl:template match="gloss">
</xsl:template>C'est tout.
En fait, non, ça n'est pas tout : on a un programme dans un langage étrange (XSLT), il faut encore l'exécuter. Pour cela il faut un interpréteur XSLT. J'ai choisi la bibliothèque libxslt de gnome, appelée depuis Perl de la manière suivante [Je m'apperçois en écrivant ces lignes qu'il existe en fait une commande qui fait déjà ça : xsltproc. Mais elle apparait 30% plus lente et deux fois plus grourmande en mémoire que mon petit script.] :
#! perl -w use strict; use XML::LibXSLT; use XML::LibXML; die "usage $0 foo.xslt foo.xml" unless scalar @ARGV == 2; my $parser = XML::LibXML->new(); my $xslt = XML::LibXSLT->new(); my $source = $parser->parse_file($ARGV[1]); my $style_doc = $parser->parse_file($ARGV[0]); my $stylesheet = $xslt->parse_stylesheet($style_doc); my $results = $stylesheet->transform($source); print $stylesheet->output_string($results);
On aurait aussi pu choisir sablotron (j'ai essayé et je l'ai trouvé trop gourmant en mémoire) ou xalan (pour ceux qui aiment Java -- je n'ai pas osé essayer).
http://xmlsoft.org/XSLT/ http://search.cpan.org/search?dist=XML-LibXSLT http://www.gingerall.com/charlie/ga/xml/p_sab.xml http://xml.apache.org/xalan-j/getstarted.html
Écrire un programme XSLT qui extrie les entrées allemandes du dictionnaire.
Écrire un programme XSLT qui extraie les entrées anglaises du dictionnaire.
Écrire un dictionnaire qui extraie les entrées prioritaires (avec une priorité quelconque : ichi1, jdd1 ou gai1).
J'utiliserai le module XML::LibXML de Perl, qui appelle la bibliothèque libxml de Gnome. (Il y a un autre module qui fait la même chose, XML::DOM, mais il est moins performant).
On lit un fichier (ici, passé en argument sur la ligne de commande) de la manière suivante.
#! perl -w use strict; use XML::LibXML; my $parser = new XML::DOM::Parser; my $doc = $parser->parsefile ($ARGV[0]); my $root = $doc->getDocumentElement;
Nous aurons besoin des méthodes suivantes (rien d'autre).
getElementsByTagName : liste des noeuds fils (ou petits-fils) avec un nom donné getFirstChild : premier noeud fils getData : contenu d'un noeud texte
Je vais maintenant exposer (des extraits simplifiés) du programme convertissant le dictionnaire en LaTeX.
On commence par récupérer les blocs <entry> (je reconnait que c'est un peu violent : nous verrons plus loin comment être un peu moins gourmant en mémoire) et par boucler dessus.
foreach my $entry (@{ $root->getElementsByTagName("entry") }) {
...
}Ensuite, on prend la liste de toutes les écritures
my $keb = $entry->getElementsByTagName("k_ele");on ne veut pas les noeuds contenant les écritures, mais simplement les écritures elles-mêmes.
my @keb = map { $_->getElementsByTagName("keb")->[0]->getFirstChild->getData }
(@$keb);On procède de même pour les lectures. Comme les entrées du dictionnaire seront ordonnées selon la prononciation, on fait boucle sur les différentes prononciations. Une entrées dans JMdict sera donc éclatée en plusieures entrées dans le dictionnaire en LaTeX.
my $r_ele = $entry->getElementsByTagName("r_ele");
foreach my $r (@$r_ele) {
my $current_reading = $r->getElementsByTagName("reb")->[0]
->getFirstChild->getData;Chaque entrées aura donc une prononciation et un nombre variable d'écritures. Dès maintenant, les choses se compliquent (c'est pour ça que je n'utilise pas XSLT) : s'il y a un bloc <re_restr>, il ne fait pas mettre toutes les prononciations.
my $re_restr = $r->getElementsByTagName("re_restr");
my @writings;
if( $re_restr->getLength >0 ){
@writings = map { $_->getFirstChild->getData } (@$re_restr);
} else {
@writings = @keb;
}On affiche prononciation et écritures.
if( scalar @writings > 0 ){
print "\\reading{$current_reading}";
print "\\writing{". join(', ', @writings) ."} ";
} else {
print "\\reading{$current_reading} ";
}On récupère ensuite les différentes notes, grammaticales et autres.
my $info = $entry->getElementsByTagName("info");
foreach my $i (@$info) {
# On oublie links, bibl, etym, audit
my $r;
$r = $i->getElementsByTagName("lang");
push @rem, map {$_->getFirstChild->getData} (@$r);
$r = $i->getElementsByTagName("dial");
push @rem, map {$_->getFirstChild->getData} (@$r);
}
my $sense = $entry->getElementsByTagName("sense");
my @rem;
foreach my $s (@$sense) {
my $r;
$r = $s->getElementsByTagName("gram");
push @rem, map {$_->getFirstChild->getData} (@$r);
$r = $s->getElementsByTagName("field");
push @rem, map {$_->getFirstChild->getData} (@$r);
$r = $s->getElementsByTagName("misc");
push @rem, map {$_->getFirstChild->getData} (@$r);
}On les affiche.
if( scalar @rem >0 ){
print " ". join(" ",
map { "\\gram{$_}" } @rem
) ;
}On affiche ensuite toutes les traductions, en tenant compte des restrictions <stagk> et <stagr>.
foreach my $s (@$sense) {
my $gloss = $s->getElementsByTagName("gloss");
my $stagr = $s->getElementsByTagName("stagr");
if($stagr->getLength >0){
my $stay_here = FALSE;
foreach my $res (@$stagr) {
$stay_here = TRUE
if $res->getFirstChild->getData eq $current_reading;
}
next unless $stay_here;
}
print ' \a ';
my $stagk = $s->getElementsByTagName("stagk");
if($stagk->getLength >0){
print "\\stagk{". join(', ',
map { $_->getFirstChild->getData } (@$stagk)
) ."} ";
}
my @glosses = map { $_->getFirstChild->getData } (@$gloss);
print "\\defi{";
print join('; ', @glosses);
print ".} $newline";C'est tout.
Ce qui précède est une version simplifiée du programme. Voici ce que j'ai passé sous silence.
(Ne lisez ce qui suit que si vous avec trouvé la discussion précédente un peu trop simpliste. Si ce n'est pas le cas, passez directement à la section suivante.)
Pour cela, on peu couper le fichier en morceuax, avec une seule entrée par fichier. On peut faire cela de manière barbare (en oubliant qu'il s'agit de fichiers XML). La variable $/ contient ce qui constitue, pour Perl, la fin d'une ligne.
$/="</entry>";
while(my $entry = <>){
$entry =~ s|^.*<JMdict>||sm;
$entry =~ s|</JMdict>.*||sm;
next if $entry =~ m/^\s*$/s;
print STDERR "*";
process_entry_with_DOM("<JMdict>". $entry ."</JMdict>");
}ou de manière plus civilisée (en se rappelant qu'il s'agit d'un fichier XML).
use XML::Twig;
my $twig=XML::Twig->new( twig_handlers => { entry => \&entry } );
$twig->parsefile($ARGV[0]);
$twig->flush;
sub entry {
my ($t, $entry) = @_;
process_entry_with_DOM("<JMdict>". $entry->sprint ."</JMdict>");
$t->purge;
}En fait, ça ne marche pas très bien, car il y a une fuite de mémoire dans XML::DOM, que je viens de signaler. http://rt.cpan.org/NoAuth/Bug.html?id=526
Nous avons besoin de connaître le premier caractère des mots, d'une part pour indiquer chaque changement de lettre, d'autre part pour mettre des onglets dans la marge indiquant la lettre courrante. Le problème, c'est que le texte est en UTF8.
Je rappelle qu'Unicode est un jeu (i.e., ensemble) de caractère, qui couvre la plupart des langues vivantes : il permet donc d'écrire un texte avec à la fois des caractères asiatiques et des caractères latins accentués.
UTF8 est l'un des codages que l'on peut utiliser pour taper du texte en Unicode (il y en a d'autres, par exemple UCS2). Un codage, c'est ce qui permet de transformer une suite d'octets comme une suite de caractères : il faut regrouper les octes deux par deux, parfois trois par trois, pour avoir des caractères.
Le problème, c'est que Perl a tendance à considérer les chaines de caractères comme des suites d'octets, il faut donc être très soigneux quand on lui demande de prendre le premier caractère codé en UTF8 : parfois, ce sera un seul octet, parfois deux octets, parfois trois octets.
Une première manière de procéder consiste à remarquer que les caractères unicodes utf8 sont (en binaire) de l'une des formes suivantes.
0xxxxxxx 110xxxxx 10xxxxxx 1110xxxx 10xxxxxx 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Ils sont par conséquent reconnus par l'expression régulière suivante (non testée).
$middlechar = qr{[\x80-\xBF]};
$char = qr{ [\x00-\x7F] |
[\xC0-\xDF] $middlechar |
[\xE0-\xEF] $middlechar $middlechar |
[\xF0-\xF8] $middlechar $middlechar $middlechar |
[\xF8-\xFC] $middlechar $middlechar $middlechar $middlechar |
[\xFD-\xFE] $middlechar $middlechar $middlechar $middlechar $middlechar
}x;Une autre manière de procéder consiste à utiliser le fait que Perl sait quand même reconnaître les caractères en UTF8. Le problème, c'est que dans la version stable actuelle (5.6, à l'heure à laquelle j'écris ces lignes, mais ça va bientôt changer) le support d'UTF8 est expérimental et changera complètement dans la version suivante. J'ai testé l'actuelle version de développement, mais elle n'est pas encore suffisemment stable (c'était la première fois que Perl me faisait un Segmentation Fault...). Pour information, dans la vieille version, on disait qu'un morceau de code érait en UTF8, alors que dans la nouvelle on dit qu'un flux (un fichier, une chaine de caractères) est en utf8 (ou dans un autre codage). On oublie donc cette deuxième manière de procéder.
Une dernière manière de procéder (c'est ce que j'ai choisi) consiste à utiliser le module Unicode::String.
use Unicode::String qw(utf8 latin1); ... my $first = utf8($current_reading); $first = $first->substr(0,1); $first = $first->utf8;
Toujours pour la première lettre des mots, mais aussi pour pouvoir les trier.
Une première solution consiste à utiliser une grosse suite d'expressions régulières (le codage utf8, rappelé plus haut, est tel qu'il n'y a aucun risque de couper des caractères en deux -- ce risque existe avec d'autres codages, tels EUC-JP).
s/ア/あ/g; s/イ/い/g; ...
Une autre solution consiste à découper la chaine en caractères et à les convertir un par un, en utilisant une table de hachage.
our %kata2hira = qw/ア あ ァ ぁ .../;
sub katakana_to_hiragana_character {
my $a = shift;
if( exists $kata2hira{$a} ){
return $kata2hira{$a};
} else {
return $a;
}
}
sub katakana_to_hiragana {
my $a = shift;
$a = utf8($a) unless ref $a;
for(my $i=0; $i < $a->length; $i++){
$a->substr($i,1,
katakana_to_hiragana_character($a->substr($i,1)));
}
return $a;
}Dans tous les cas, on n'oublie pas que le ー n'existe pas en hiragana. On s'en débarasse ainsi.
s/(あ|ぁ|か|が|さ|ざ|た|だ|な|は|ば|ぱ|や|ゃ|わ)ー/$1あ/g; s/(い|ぃ|き|ぎ|し|じ|ち|ぢ|に|ひ|び|ぴ)ー/$1い/g; s/(う|ぅ|く|ぐ|す|ず|つ|づ|ぬ|ふ|ぶ|ぷ|ゆ|ゅ)ー/$1う/g; s/(え|ぇ|け|げ|せ|ぜ|て|で|ね|へ|べ|ぺ)ー/$1え/g; s/(お|ぉ|こ|ご|そ|ぞ|と|ど|の|ほ|ぼ|ぽ|よ|ょ|を)ー/$1お/g;
Rappelons les règles de tri pour le japonais (ou du moins la manière dont je les ai comprises).
http://omega.cse.unsw.edu.au:8080/papers/bite.ps
1. On commence tout d'abord par convertir les mots en hiragana (lors de cette convertion, on remplace le symbole d'allongement par la voyelle précédente), on enlève les accents (nigori) et on donne la même taille à chaque caractère.
s/ば/は/g; s/ぱ/は/g; ... s/っ/つ/g; s/ゃ/や/g; s/ぁ/あ/g; ...
On les commpare alors, suivant l'ordre usuel あいうえおかきくけこ...
2. Si les mots sont les mêmes après cette transformation, on les regarde caractère par caractère. Les petites lettres viennent avant les grandes, celles avec nigori viennent après ; les hiragana viennent avant les katakana.
ー < ぁ < ァ < あ < ア か < カ < が < ガ っ < ッ < つ < ツ < づ < ヅ は < ハ < ば < バ < ぱ < パ ...
Par exemple, les "mots" suivants sont dans le bon ordre.
あー ああ アー アア しゃ しや しゃべる はは ハハ はば ハバ はぱ ハパ ばは バハ ばぱ バハ ぱは パハ ぱは パハ ぱば パバ ぱぱ パパ
On s'attendrait (bien sûr) à ce que les locales permettent ce genre de chose. En Perl, on écrirait
use POSIX qw(locale_h);
...
{
use locale;
setlocale(LC_COLLATE, "ja_JP.utf8");
... sort ...
}et en shell
LC_COLLATE=ja_JP.utf8 sort essai.utf8
Mais ça ne marche pas : il ne ignore la correspondance entre hiragana et katakana, et l'existence de petits kana.
あー ああ しゃ しゃべる しや はは はば はぱ ばは アー アア ハハ ハバ ハパ バハ
J'ai tout d'abord commencé par écrire une fonction de comparaison, que je donnais en argument de la fonction Perl sort.
sub japanese_compare { ... }
sort japanese_compare @lines;Mais c'est beaucoup trop lent et trop gourmand en mémoire. Je me retourne donc sur la commande UNIX sort, qui ne sait pas trier le japonais, certes, mais qui est capable de trier efficacement des chaines de caractères ASCII. Nous allons donc rajouter, au début des lignes que nous voulons trier, une chaine de caractères ascii qui correspond à la conversion en hiragana (sans nigori).
あ,ぁ,ア,ァ -> 00 い,ぃ,イ,ァ -> 01 う,ぅ,ウ,ゥ -> 02 え,ぇ,エ,ェ -> 03 お,ぉ,オ,ォ -> 04 ...
Par exemple
しゃしん -> 0E260E32
Ensuite, après un espace, nous mettons une deuxième chaine de caractères, qui correspond à la différence entre les caractères qui donnent le même hiragana.
ー -> 00 ぁ -> 01 あ -> 02 ァ -> 03 ア -> 04 ー -> 00 ぃ -> 01 い -> 02 ィ -> 03 イ -> 04 ...
Par exemple
しゃしん 0E260E32 01010101 シャシン 0E260E32 02020202 プライバシー 1E29041C0E04 060204040200
Voici le programme :
%rank = { ぁ => 1, ァ => 1, あ => 1, ア => 1,
ぃ => 2, ィ => 2, い => 2, イ => 2,
...
};
%subrank = { ー => 0,
ぁ => 1, ァ => 2, あ => 3, ア => 4,
ぃ => 1, ィ => 2, い => 3, イ => 4,
...
};
sub kana_sort_key_simple {
print STDERR "(in) kana_sort_key_simple\n" if DEBUG;
my $pron = shift;
$pron = $pron->utf8 if ref $pron;
$pron = katakana_to_hiragana($pron);
my $ans="";
$pron = utf8($pron) unless ref $pron;
for(my $i=0; $i < $pron->length; $i++){
my $char = $pron->substr($i,1)->utf8;
my $n;
if( exists $Kana::rank{$char} ){
$n = $Kana::rank{$char};
} else {
$n = 0;
warn "Strange character `$char'";
}
$ans .= sprintf("%02X", $n);
}
print STDERR "(out) kana_sort_key_simple\n" if DEBUG;
return $ans;
}
sub kana_sort_key_complex {
print STDERR "(in) kana_sort_key_complex\n" if DEBUG;
my $pron = shift;
$pron = utf8($pron) unless ref $pron;
my $ans="";
for(my $i=0; $i < $pron->length; $i++){
my $char = $pron->substr($i,1)->utf8;
my $n;
if( exists $Kana::subrank{$char} ){
$n = $Kana::subrank{$char};
} else {
$n = 0;
warn "Strange character `$char'";
}
$ans .= sprintf("%02X", $n);
}
print STDERR "(out) kana_sort_key_complex\n" if DEBUG;
return $ans;
}
Les traductions sont entièrement en minuscules : il va falloir mettre une majuscule au début de chaque liste de traductions. Pour ce faire, on utilise la fonction Perl ucfirst (sous la forme \u). On commence tout d'abord par essayer
use POSIX qw(locale_h);
...
{
use locale;
setlocale(LC_CTYPE, "fr_FR.utf8");
$text =~ s/^(.)/\u$1/g;
}Mais ça ne marche pas... Par exemple, il ne touche pas à la lettre É.
On essaye donc de passer d'abord en latin1 (en faisant attention à l'absence des caractères oe et OE), pour mettre la majuscule, et enfin repasser en utf8.
use Unicode::String qw(utf8 latin1);
use POSIX qw(locale_h);
...
$text =~ s/œ/\\oe /g; # U+153
$text = utf8($text);
$text = $text->latin1;
{
use locale;
setlocale(LC_CTYPE, "fr_FR.ISO8859-1");
$text =~ s/^(.)/\u$1/g;
$text =~ s/^\((.)/\(\u$1/g;
$text =~ s/^\\oe/\\OE/g;
}
$text = latin1($text);
$text = $text->utf8;
LaTeX (prononcer "latek", car le X qui est à la fin est en fait un Chi (une lettre grecque, prononcer "ki") majuscule) est un traitement de texte. Mais le traitement de texte WYSIWYG auquel on peut être habitué : il fonctionne à la manière d'un compilateur. On écrit un fichier, en utilisant un certaine langage de formatage (LaTeX), exactement comme on écrirait un programme en C, en Java ou en Perl. Ensuite, on compile ce fichier, pour avoir quelque chose de visualisable ou d'imprimable.
Les avantages de LaTeX sur les logiciels WYSIWYG sont les suivants.
D'une part, on peut facilement automatiser la création d'un fichier LaTeX (i.e., écrire un programme qui va écrire un fichier LaTeX que l'on pourra ensuite compiler puis imprimer -- c'est justement ce que nous allons faire).
D'autre part, comme il n'est pas WYSIWYG, on n'insiste pas sur la présentation du document ("je veux telle fonte, avec telle couleur, de telle taille") mais sur la structure du document ("ceci est un titre de chapitre", "ceci est un titre de section", etc.) : on définit, séparément, la correspondance entre structure et présentation. On n'a donc pas à répéter à chaque nouveau chapitre quelle fonte il faut utiliser pour le titre -- ce qui permet, par exemple, de la changer très facilement. C'est d'autant plus vrai que LaTeX est aussi un langage de programmation : si on veut faire quelque chose qui n'est pas prévu (par exemple, si la structure de notre document n'est pas standard), on peut l'impémenter nous-même.
Enfin, les algorithmes utilisés par LaTeX pour décider de la mise en page (césure des mots, coupure des lignes, des mots) sont plus performants que ceux des systèmes WYSIWYG.
Un fichier LaTeX ressemble à la chose suivante.
\documentclass[a4paper,12pt]{article}
\usepackage[latin1]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{amsmath,amssymb}
\usepackage[english,frenchb]{babel}
\author{Moi Même}
\titre{Premier document}
\date{19 avril 2002}
\begin{document}
\maketitle
\section{Introduction}
Bla bla bla bla, bla bla bla, bla bla bla. Bla bla bla
bla, bla bla bla, bla bla bla. Bla bla bla bla, bla bla
bla, bla bla bla. Bla bla bla bla, bla bla bla, bla bla
bla. Bla bla bla bla, bla bla bla, bla bla bla. Bla bla
bla bla, bla bla bla, bla bla bla.
Bla bla bla bla, bla bla bla, bla bla bla. Bla bla bla
bla, bla bla bla, bla bla bla. Bla bla bla bla, bla bla
bla, bla bla bla. Bla bla bla bla, bla bla bla, bla bla
bla. Bla bla bla bla, bla bla bla, bla bla bla. Bla bla
bla bla, bla bla bla, bla bla bla.
\section{Conclusion}
Bla bla.
\end{document}Tout ce qui commence par un antislash \ est une commande. Les arguments éventuels sont entre accolades.
Tout ce qui se trouve avant la ligne \begin{document} est le préambule du document : on y charge certains fichiers contenant des macros que l'on va utiliser. Le texte vient ensuite.
Les lignes blanches indiquent des changements de paragraphes.
Pour plus de détails, voir
http://www.loria.fr/services/tex/general/flshort2e.dvi
Le paquetage multicol permet d'écrire en deux colonnes. On précise qu'on ne veut pas de ligne orpheline, i.e., on ne veut pas que la dernière ligne d'un paragraphe se retrouve toute seule en haut d'une colonne.
\usepackage{multicol}
...
\begin{multicols}{2}
\widowpenalty=10000
\clubpenalty=10000
\raggedcolumns
...
\end{multicols}
On veut trois versions du dictionnaire : en anglais, en français et en allemand. Il n'y a pas que les entrées qui vont changer : il y a aussi le titre du dictionnaire (dictionnary, dictionnaire, Wörterbuch), les renvois (see also, voir aussi, siehe auch), la traduction des abbréviations. S'il n'y avait que peu de choses à traduire, on ferait simplement
\def\dictionarytitle{Japanese--English dictionary}
\def\seealso#1{See also {\cyber #1}}Mais pour les abréviations, on va procéder différemment : par exemple pour l'abbréviation hum, on définit des macros (sans les espaces).
abbrev english lang hum abbrev french lang hum abbrev german lang hum
Ensuite, quand on veut utiliser une de ces macros, on regarde si la macro correspondant au langage courrant existe, sinon, on émet un message d'avertissement et on prend la version anglaise.
Voici le code qui s'occupe de cela.
%% Abbréviations
\def\defineabbrev#1#2#3{%
\expandafter\def\csname abbrev#1lang#2\endcsname{#3}}
\def\explainabbrev#1{%
\leavevmode\noindent
\hangindent=1.5cm
\hbox to 1.5cm{\textit{#1}\hss}%
\expandafter\ifx\csname abbrev\currentlanguage lang#1\endcsname\relax
\csname abbrevenglishlang#1\endcsname
\csname @latex@warning@no@line\endcsname{Undefined abbreviation `#1' for language `\currentlanguage'}%
\else
\csname abbrev\currentlanguage lang#1\endcsname
\fi
\par}
%% Internationalisation : valeurs par défaut
\def\dictionarytitle{Japanese--English dictionary}
\def\currentlanguage{english}
\def\setlanguage{\selectlanguage{english}}
\def\seealso#1{See also {\cyber #1}}
\input{abbrev.english.tex}
\input{abbrev.english.supplement.tex}
%% Internationalisation : chargement des valeurs pour la langue
%% effectivement utilisée.
\makeatletter
\def\setlanguage{\language=\l@french}
\makeatother
\def\setlanguage{\selectlanguage{french}}
\def\currentlanguage{french}
\IfFileExists{localisation.french.tex}{\input{localisation.french.tex}}{}Pour une langue autre que le français, il suffira de remplacer toutes les occurrences de « french », par exemple par « german ».
Nous voulons mettre en page un dictionnaire. Pour cela, nous voudrions avoir, en haut de chaque page, le premier mot de la page, le dernier mot de la page, et aussi la lettre courrante. Pour savoir quel est le premier mot apparaissant sur la page, le dernier mot apparaissant sur la page précédente et dont la définition se poursuit sur la page courrante, et le dernier mot de la page, nous allons utiliser des marques (respectivement \firstmark, \topmark, \botmark). Nos entrées du dictionnaire ressembleront à
\newentry
\markboth{くるま}{く}
\reading{くるま}
\writing{車}
...En fait, nous n'aurons pas besoin de deux marques, mais de trois. LaTeX est conçu pour en manipuler seulement deux, donc on définit de nouvelles fonctions.
\def\markthree#1#2#3{\gdef\@themark{{#1}{#2}{#3}}{%
\let\protect\@unexpandable@protect
\let\label\relax \let\index\relax \let\glossary\relax
\mark{\@themark}}\if@nobreak\ifvmode\nobreak\fi\fi}
\long\def\@firstofthree#1#2#3{#1}
\long\def\@secondofthree#1#2#3{#2}
\long\def\@thirdofthree#1#2#3{#3}
\def\firstword{\expandafter\@firstofthree\firstmark{}{}{}}
\def\lastword{\expandafter\@firstofthree\botmark{}{}{}}
\def\firstkana{\expandafter\@secondofthree\firstmark{}{}{}}
\def\firstkanabox{\expandafter\@thirdofthree\firstmark{}{}{}}
Pour faire joli, on aimerait avoir la liste de tous les caractères sur le bord de la page, avec le caractère courrant sur un disque coloré.
Nous commençons par écrire une macro pour mettre un caractère sur un disque coloré (à l'aide de PSTricks).
\usepackage{pstricks,calc}
\newlength\kanawidth
\newlength\kanaheight
\def\verticalcircle#1{%
\settowidth{\kanawidth}{#1}%
\settoheight{\kanaheight}{#1}%
\addtolength{\kanaheight}{\depthof{#1}}%
\vbox to \kanaheight{%
\vss
\hbox to \kanawidth{%
\hss
\hbox{\pscirclebox[framesep=0pt,fillcolor=yellow,fillstyle=solid,linecolor=yellow]{#1}}%
\hss
}%
\vss
}%
}Voici maintenant une macro qui prend deux argument, le premier caractère du mot courrant et le caractère que l'on s'apprète à écrire sur le bord de la page. S'ils sont égaux, on le place sur un disque coloré.
\global\def\kanaboxitem#1#2{%
\hbox{\ifthenelse{\equal{#1}{#2}}{\verticalcircle{\textbf{#2}}}{#2}}%
\vskip 3pt
}Mais en fait, ça ne va pas marcher, car il y a trop de caractères pour la hauteur de la page. Nous allons donc juste mettre le premier caractère de chaque série (あ,か,さ,た...). il nous faut donc une macro à trois arguments
\global\def\kanaboxitem#1#2#3{%
\hbox{\ifthenelse{\equal{#1}{#3}}{\verticalcircle{\textbf{#2}}}{#3}}%
\vskip 3pt
}que nous appellerons ainsi : le premier argument est le premier caractère du mot courrant, sans nigori, et avec la voyelle あ, le second est le premier caractère du mot (sans nigori), le troisième est le caractère que l'on s'apprette à écrire.
% Dans l'entrée くるま
\kanaboxitem{か}{く}{あ}
\kanaboxitem{か}{く}{か}
\kanaboxitem{か}{く}{さ}
\kanaboxitem{か}{く}{た}
\kanaboxitem{か}{く}{な}
\kanaboxitem{か}{く}{は}
...Voici maintenant une macro qui construit une boite avec tout ce que l'on veut voir dans la marge extérieure de la page.
\def\kanabox#1#2{%
\vskip 2cm%
\kanaboxitem{#1}{#2}{あ}%
\vfill
\kanaboxitem{#1}{#2}{か}%
\vfill
\kanaboxitem{#1}{#2}{さ}%
\vfill
\kanaboxitem{#1}{#2}{た}%
\vfill
\kanaboxitem{#1}{#2}{な}%
\vfill
\kanaboxitem{#1}{#2}{は}%
\vfill
\kanaboxitem{#1}{#2}{ま}%
\vfill
\kanaboxitem{#1}{#2}{や}%
\vfill
\kanaboxitem{#1}{#2}{ら}%
\vfill
\kanaboxitem{#1}{#2}{わ}%
\removelastskip
\vskip 2cm%
}
Il n'y a rien de vraiment prévu pour écrire dans la marge des pages. Le paquetage fancyhdr permet d'écrire facilement en haut et en has des pages : on peut le détourner pour écrire dans la marge. Pour cela, nous allons utiliser des « ressorts qui font des trous », \hss pour les trous horizontaux et \vss pour les trous verticaux.
Par exemple, si on demande à fancyhdr de mettre en haut à droite d'une page
\hbox to 0pt{Bla bla bla\hss}le texte va se trouver dans la marge. Il nous suffit donc de faire cela à la fois avec une boite horizontale (pour se placer dans la marge) et avec une boite verticale (pour $etre à peu près au milieu de la page).
Voici le code :
\def\rlap#1{\hbox to 0pt{#1\hss}}
\def\llap#1{\hbox to 0pt{\hss#1}}
\fancyhf{}
\fancyhead[RO]{%
\leavevmode
\hbox{%
\cyber
\firstword\myemdash\lastword
}
\rlap{\hspace{1em}\vbox to 0pt{%
\null
\vspace{\headsep}%
\vspace{3pt}%
\vbox to \textheight{%
\cyber \firstkanabox
}%
\vss
}}%
}
\fancyhead[LE]{%
\leavevmode
\hbox{%
\cyber
\llap{\vbox to 0pt{%
\null
\vspace{\headsep}%
\vspace{14pt}%
\vbox to \textheight{%
\firstkanabox
}%
\vss
}\hspace{1em}}%
\firstword\myemdash\lastword
}
Jusqu'ici, c'est bien beau, mais nous avons supposé que LaTeX était naturellement capable de mettre en page du texte en UTF8 mélangeant du japonais et des caractères (accentués) français, ce qui est complètement faux. Nous allons maintenant voir comment y remédier.
LaTeX est un traitement de texte archaïque (mais comme il n'y a rien de mieux...), conçu initialement pour traiter la langue anglaise. On peut sans trop de problèmes taper du texte dans les langues alphabétiques, même accentuées, mais l'utilisation avec des langues asiatiques relève du bricolage. Le bricolage fonctionne ainsi : on charge le paquetage CJK et on place le texte asiatique dans un environement CJK ou CJK* (dans l'environement CJK*, il ne fait pas attention aux espaces, ce qui est préférable pour le texte asiatique : sinon les retours à la ligne seraient considérés comme des espaces).
\documentclass[12pt]{article}
\usepackage{CJK}
\usepackage[T1]{fontenc}
% we want the Unicode font for normal text also
\DeclareFontFamily{T1}{song}{}
\DeclareFontShape{T1}{song}{m}{n}{<-> cyberb00}{}
\renewcommand\rmdefault{song}
\begin{document}
\begin{CJK*}{UTF8}{song}
これはサンプル文章です。
\end{CJK*}
\end{document}Il y a toutefois un GROS problème : les fontes. Il faut une fonte qui contienne les caractères dont on a besoin. En cherchant sur internet, on finit par trouver un fichier cyberbit.ttf. On peut vérifier qu'il contient bien les caractères dont on a besoin à l'aide de la commande ftview (qui fait partie de FreeType2).
ftview 100 cyberbit.ttf


Il faut ensuite faire comprendre cette fonte à LaTeX. On a besoin de plusieures choses : d'une part les métriques de la fonte, i.e., la taille de chacun des caractère -- LaTeX attend ces informations dans un fichier *.tfm. Ensuite, pour visualiser ou imprimer le fichier obtenu, il faut le dessin des caractères : xdvi ou dvips les attendent dans des fichiers *.pk. Si ces fichiers ne sont pas là, il faut que dvips/xdvi sache comment les créer à l'aide du fichier ttf ; pour cela il faut qu'ils connaissent la correspondance entre le nom de la fonte pour LaTeX (cyberb) et le nom du fichier PostScript -- c'est contenu dans le fichier ttfonts.map. Dernier détail : comme LaTeX ne comprend que des fontes d'au plus 256 caractères, il va falloir couper notre fonte en morceaux (cyberb00, cyberb01, etc.).
On peut procéder ainsi :
http://www.math.jussieu.fr/~zoonek/LaTeX/FontInstallUnicode/
Pour une utilisation normale, ça marche très bien. Mais nous allons avoir besoin de rentrer et de sortir de l'environement CJK à chaque entrée du dictionnaire (par exemple, pour ne pas avoir de problème poue taper des caractères accentués, pour avoir une césure correcte, ou pour avoir une autre fonte). Or il se trouve qu'à chaque environement CJK, LaTeX va charger les fichiers UTF8.enc et UTF8.chr. Or, à chaque fois que LaTeX charge un fichier, il l'affiche à l'écran et dans un fichier *.log. Or, la taille de ce fichier est limitée : avec le dictionnaire entier, on atteint très vite (au bout d'un dixième du dictionnaire) cette limite et LaTeX plante avec un joli message
string pool overflow [750000 bytes]
Pour contourner ce problème, nous utiliserons Omega.
Omega est une version multilingue de TeX (Lambda est l'équivalent pour LaTeX), qui utilise Unicode (sous le codage UCS2) de manière interne.
Un fichier Omega en UTF8 ressemble à
\ocp\TexUTF=inutf8
\InputTranslation currentfile \TexUTF
\documentclass[twoside]{article}
...
\begin{document}
Du texte en UTF8, avec des lettres accentuées
\end{document}
Si on veut utiliser des fontes (latines) non standard, ça marche exactement comme sous LaTeX.
Mais comme précédemment, si on veut mettre du texte en japonais, il faut lui dire où trouver les fontes. J'explique cela dans la seconde partie du document mentionné précédemment.
http://www.math.jussieu.fr/~zoonek/LaTeX/FontInstallUnicode/
Si on regarde les messages de Lambda quand il compile un fichier, on constate qu'il ne connait pas les motifs de césure pour le français ou l'allemand (deux langues dont nous aurons besoin).
This is Omega, Version 3.14159--1.15 (Web2C 7.3.3.1) Copyright (c) 1994--2000 John Plaice and Yannis Haralambous LaTeX2e <1999/12/01> patch level 1 Hyphenation patterns for english, greek, loaded.
Nous allons donc devoir recompiler le format : LaTeX est un ensemble de macros écrites en TeX, qui prendraient plus de 600 pages si on les imprimait ; pour accélérer le chargement, ces macros ne sont pas lues et interprétées à chaque fois : elles sont lues directement sous une forme précompilée -- un format, dans un fichier latex.fmt ou lambda.fmt. Il y a certaines choses qui doivent être précisées lors de la création du format, par exemple les motifs de césure. La liste des motifs de césure est dans un fichier language.dat. Il y en a un particulier pour Lambda.
texmf/omega/lambda/base/language.dat texmf/source/generic/babel/language.dat texmf/source/latex/platex/language.dat texmf/tex/platex/config/language.dat texmf-var/tex/generic/config/language.dat
Le plus simple est de placer le fichier language.dat désiré dans un répertoire, de lancer
lambda --ini lambda.ini
puis de mettre le format ainsi créé *.fmt à l'endroit voulu (dans le répertoire courant ou dans texmf/web2c/)
On peut maintenant vérifier que la césure française fonctionne sans problème sous Lambda.
\ocp\TexUTF=inutf8
\InputTranslation currentfile \TexUTF
\documentclass{article}
\usepackage[english,german,frenchb]{babel}
\begin{document}
\showhyphens{essai}
\showhyphens{école}
\showhyphens{éducation}
\selectlanguage{german}
\showhyphens{stoßen auf}
\showhyphens{sto\ss en auf}
\end{document}(Je suis persuadé que ce qui précède ne devrait pas marcher. Mais ça marche quand-même.)
Pour la typographie française (l'espace avant ;:?!» ou après « est insécable), il ne devrait pas y avoir de problème, car Babel s'en charge, en rendant ces caractères actifs.
Pour la typographie japonaise, par contre, il faut s'en charger (CJK s'en chargeait en rendant actifs le premier octet des caractères UTF8). En japonais, contrairement à ce que l'on croit souvent, on n'a pas le droit de couper les mots n'importe où : c'est interdit avant des caractères comme
。、」)]ーぁァぃィぅゥぇェぉォっッゃャゅュょョ (petits kana)
ou après des caractères comme
(「[
Pour respecter ces règles (pour les symboles de ponctiation, elles sont bien respectées, mais rarement pour les petits kana), on peut soit jouer sur l'espace entre les lettres, soit accepter de déborder un peu sur le bord droit de la page.
Pour implémenter ces règles, on peut écrire des OTP (Omega Translation Process) qui vont rajouter des instructions disant qu'on peut couper/déborder ou pas après certains caractères. Je détaille cela dans un autre document.
http://www.math.jussieu.fr/~zoonek/UNIX/37_omega_OTP/otp.txt
Sous Omega, avec la fonte standard d'Omega, le caractère oe disparait et le caractère ß disparait ou se transforme en SS. Pour contourner ce problème, je les ai donc convertis en \oe et \SS. J'espère qu'il n'y a pas d'autres caractères comme ça...
Ça doit provenir d'un problème de codage des fontes : il faudrait soit utiliser une fonte Unicode qui contienne tous les caractères latins dont on a besoin (par exemple, cyberbit) ou créer une fonte virtuelle avec les caractères CM pour le texte latin et les caractères d'une fonte TTF Unicode pour le reste.
Nous avons déjà expliqué plus haut pourquoi nous avons choisi Oméga plutôt que latex+CJK (ce dernier ne permet pas facilement de traiter de gros documents dans lesquels on passe sans cesse d'une langue à une autre).
Mais il existe une autre variante de LaTeX qui permet de mettre en page du japonais : platex. Je ne l'ai pas retenue, car d'une part, bien que très répandue au Japon, elle est pratiquement inconnue en occident, d'autre part, elle ne permet (à ma connaissance) de traiter que du texte en EUC et en SJIS, ce qui ne permet pas très facilement de mélanger du texte japonais et du texte français.
En contrepartie, platex est beaucoup plus stable qu'Oméga.
Oméga présente lui aussi quelques défauts : s'il permet d'écrire dans n'importe quelle langue, il faut tout faire soi-même (un peu comme si on disposait de TeX-le programme sans PlainTeX ni LaTeX) : lui expliquer quelle fonte utiliser, quel codage utiliser, mettre en oeuvre les règles typographiques ou de césure, etc.
Il aurait mieux valu garder du XML d'un bout à l'autre :
Dans un premier temps, on extrait la partie du dictionnaire qui nous intéresse (langue, priorité) ;
Dans un second temps, on éclate chacune des entrées en autant de prononciations qu'elle contient, de manière que les entrées correspondent à ce que l'on veut voir imprimé sur le dictionnaire final ;
Dans un troisième temps, on « nettoie » les entrées, par exemple en se débarassant des blocs vides (qui proviendraient des blocs <sense> vides) ;
Dans un quatrième temps, on met les entrées dans l'ordre ;
Dans un cinquième temps, on modifie certaines des entrées, en particulier les entrées identiques et très proches (par contre on laisse telles-quelles les entrées identiques et lointaines).
Ainsi, on aurait un fichier XML d'un bout à l'autre (ce qui serait beaucoup plus propre que ce que j'ai fais) et c'est ce fichier XML que l'on donnerait à Oméga : il n'est pas très compliqué d'écrire des macros pour qu'Oméga comprenne <entry> comme signifiant \begin{entry}.
Vincent Zoonekynd
<zoonek@math.jussieu.fr>
latest modification on Wed Oct 22 21:50:26 CEST 2003