
J'ai écrit un script en perl qui crée (dans un répertoire) tous les fichiers nécessaires à l'utilisation d'une fonte TTF (il cherche tout seul les fichiers *.ttf dans le répertoire courrant) sous LaTeX ou Omega, ainsi que quelques fichiers d'exemple. La fonte est directement utilisable dans ce répertoire. Pour l'utiliser ou l'installer, regarder le fichier Makefile.
font_install_unicode.pl
Il vous faut aussi une fonte Unicode. Par exemple la fonte Cyberbit (actuellement disponible chez Netscape), qui est relativement complète ou les fontes Kochi (uniquement pour le japonais). Jean-Marc Desperrier maintient une liste un peu plus complète de ces fontes.
ftp://ftp.netscape.com/pub/communicator/extras/fonts/windows/ http://www.on.ics.keio.ac.jp/~yasu/linux/fonts/ http://perso.club-internet.fr/jmdesp/news/index.html
Si vous avez un problème du genre "Bad metric (TFM/OFM) file", cela provient sûrement de la version de ovp2ovf utilisée : je constate que les versions 1.15 et 2.0 ne marchent pas, alors que la version 1.11, qui était sur le CD TeXLive6 marchait très bien. Voici l'exécutable pour Linux :
ovp2ovf
Nous aurons besoin des fichiers suivants.
cyberbit.ttf
Il s'agit d'une fonte Unicode contenant les caractères dont on a besoin. N'importe quelle autre fonte Unicode conviendrait.
ttfonts.map
Ce fichier contient la correspondance entre le nom des fontes pour LaTeX (par exemple, cyberb00, cyberb01, cyberb02, etc -- il y en a plusieurs, car les fontes LaTeX comportent au maximum 256 caractères).
Son contenu ressemble à
cyberb@Unicode.sfd@ cyberbit.ttf
Lors de l'installation des fontes, il faudra concaténer ce fichier avec celui qui est présent dans votre arborescence (sans écraser ce dernier). Si votre arborescence est très en desordre, vous risquez d'avoir plusieurs fichiers qui portent ce nom. La commande suivante permet de savoir lequel LaTeX (ou dvips/xdvi) ira chercher.
kpsewhich --progname=ttf2pk --format="other text files" ttfonts.map
(Je suggèrerais même d'effacer les ttfonts.map inutilisés, car ils prètent à confusion.)
cyberb00.tfm cyberb01.tfm cyberb02.tfm cyberb03.tfm ...
Ces fichiers contiennent les métriques, i.e., largeur et hauteur de chaque caractère : c'est tout ce dont LaTeX a besoin pour composer un texte.
c70song.fd
C'est un fichier qui indique à LaTeX comment utiliser la fonte. C'est peu pertinent pour ce genre de fontes : généralement, on y trouve la description d'une famille de fontes, avec des variabltes grasses, italiques, petites capitales, etc., distinctions assez peu utilisées pour les langues asiatiques.
Son contenu ressemble à
% This is the file c70song.fd of the CJK package
% for using Asian logographs (Chinese/Japanese/Korean) with LaTeX2e
%
% created by Werner Lemberg <wl@gnu.org>
%
% Version 4.3.0 (20-Jun-1999)
\def\fileversion{4.3.0}
\def\filedate{1999/06/20}
\ProvidesFile{c70song.fd}[\filedate\space\fileversion]
% character set: Unicode U+0080 - U+FFFD
% font encoding: Unicode
\DeclareFontFamily{C70}{song}{}
\DeclareFontShape{C70}{song}{m}{n}{<-> CJK * cyberb}{}
\DeclareFontShape{C70}{song}{bx}{n}{<-> CJKb * cyberb}{\CJKbold}
\endinputEnfin, un fichier d'exemple, que l'on va pouvoir modifier à loisir. Celui-ci provient de CJK.
% This is the file UTF8.tex of the CJK package
% for testing UTF 8 encoding.
%
% written by Werner Lemberg <wl@gnu.org>
%
% Version 4.3.0 (20-Jun-1999)
\documentclass[12pt]{article}
\usepackage{CJK}
\usepackage[T1]{fontenc}
% we want the Unicode font for normal text also
\DeclareFontFamily{T1}{song}{}
\DeclareFontShape{T1}{song}{m}{n}{<-> cyberb00}{}
\renewcommand\rmdefault{song}
\begin{document}
\begin{CJK}{UTF8}{song}
\noindent Hello World!
\noindent Καλημέρα κόσμε
\CJKnospace
\noindent こんにちは 世界
\end{CJK}
\end{document}Enfin, nous aurons besoin de
cyberb00.600pk cyberb00.720pk cyberb01.600pk cyberb01.720pk cyberb02.600pk cyberb03.720pk ...
Ces fichiers contiennent le dessin des caractères, sous une forme facilement compréhensible par les programmes qui gravitent autour de LaTeX. Il s'agit de fichiers bitmap (la résolution est choisie en fonction de la taille des caractères et de l'imprimante : ici, 10 et 12 points pour une imprimante à 300ppi).
On peut le faire à la main, directement.
ttf2tfm cyberbit.ttf cyberb@Unicode@ | tail -1 > ttfonts.map
for i in cyberb*.tfm
do
ttf2pk -q ${i%.tfm} 600
ttf2pk -q ${i%.tfm} 720
done
On pourra alors compiler et visualiser l'exemple.
latex UTF8.tex xdvi UTF8.dvi dvips -o UTF8.ps UTF8.dvi gv UTF8.ps
Les fichiers dont Omega a besoin sont les suivants.
Tout d'abord le fichier ttfonts.map et les fichiers bitmap *pk.
ttfonts.map cyberb00.600pk cyberb00.720pk cyberb01.600pk cyberb01.720pk cyberb02.600pk cyberb03.720pk ...
Un fichier contenant les métriques. Cette fois-ci, un seul fichier suffira : sous Omega, les fontes ne sont plus limitées à 256 caractères.
omcyberb.ofm
Un fichier disant que pour trouver les caractères de la fonte omcyberb, il faut aller voir dans telle ou telle fonte cyberb?? : c'est ce que l'on appelle une fonte virtuelle.
omcyberb.ovf
Les métriques sont crées automatiquement à partir des fontes virtuelles : il nous suffit donc de créer le fichier omcyberb.ovf. Pour cela, on passe par un fichier intermédiaire, qui contient exactement la même chose, mais sous une forme humainement lisible : omcyberb.ovp.
Nous aurons besoin des métriques des fontes cyberb??, sous une forme humainement lisible : ce sont les fichiers cyberb??.pl.
for tf in *.tfm
do
tftopl $tf ${tf%tfm}pl
doneCes fichiers ressemblent à cela.
(FAMILY BITSTREAMCYBERBITRO) (FACE F MRR) (HEADER D 18 O 10120671145) (HEADER D 19 O 14135062544) (HEADER D 20 O 4030474440) (HEADER D 21 O 14035072146) (HEADER D 22 O 6235063155) (HEADER D 23 O 4030674542) (HEADER D 24 O 14534461151) (HEADER D 25 O 16413472164) (HEADER D 26 O 14610061151) (HEADER D 27 O 16434672162) (HEADER D 28 O 14530266543) (HEADER D 29 O 17130462562) (HEADER D 30 O 14232272162) (HEADER D 31 O 15733260556) (HEADER D 32 O 10025267151) (HEADER D 33 O 14333662145) (HEADER D 34 O 10011600000) (CODINGSCHEME CJK-UNICODE) (DESIGNSIZE R 10.0) (COMMENT DESIGNSIZE IS IN POINTS) (COMMENT OTHER SIZES ARE MULTIPLES OF DESIGNSIZE) (CHECKSUM O 25341607600) (FONTDIMEN (SLANT R 0.0) (SPACE R 0.25) (STRETCH R 0.3) (SHRINK R 0.1) (XHEIGHT R 0.4) (QUAD R 1.0) ) (CHARACTER O 0 (CHARWD R 1.0) (CHARHT R 0.715) (CHARDP R 0.157) ) (CHARACTER O 1 (CHARWD R 1.0) (CHARHT R 0.719) (CHARDP R 0.153) ) ...
Le fichier omcyberb.ovp ressemble énormément à ces fichiers *.pl. L'en-tête de ce fichier ressemblera à ceci.
(VTITLE 'BitstreamCyberbit-Roman' Omega font) (OFMLEVEL H 1) (FAMILY ombitstreamcyberbi) (FACE F MRR) (SEVENBITSAFEFLAG TRUE)(CODINGSCHEME CJK-UNICODE) (DESIGNSIZE R 10.0) (FONTDIMEN (SLANT R 0.0) (SPACE R 0.25) (STRETCH R 0.3) (SHRINK R 0.1) (XHEIGHT R 0.4) (QUAD R 1.0) )
On prend ces fimensions dans les divers fichiers *.pl correspondants. Vient ensuite la liste des sous-fontes utilisées. Elles sont numérotées consécutivement à partir de zéro : mais comme il y a des trous, ces numéros ne correspondent pas aux nom des fontes. Par exemple, la fonte bitstreamcyberbitromanfe devrait avoir le numéro 0xfe (254), mais à cause de ces trous, elle ne porte que le numéro 163. (Je ne pense pas qu'on soit obligé de les numéroter consécutivement.)
(MAPFONT D 0 (FONTNAME bitstreamcyberbitroman00) (FONTAT R 1.0) (FONTDSIZE R 10.0) ) (MAPFONT D 1 (FONTNAME bitstreamcyberbitroman01) (FONTAT R 1.0) (FONTDSIZE R 10.0) ) ... (MAPFONT D 162 (FONTNAME bitstreamcyberbitromanfd) (FONTAT R 1.0) (FONTDSIZE R 10.0) ) (MAPFONT D 163 (FONTNAME bitstreamcyberbitromanfe) (FONTAT R 1.0) (FONTDSIZE R 10.0) )
Viennent enfin les caractères. On reprend leurs dimensions dans les fichiers *.pl.
(COMMENT Begin ombitstreamcyberbitroman00)
(CHARACTER H 0000
(CHARWD R 0.5)
(MAP
(SELECTFONT D 0)
(SETCHAR O 0)
)
)
(CHARACTER H 0001
(CHARWD R 0.5)
(MAP
(SELECTFONT D 0)
(SETCHAR O 1)
)
)
(CHARACTER H 0002
(CHARWD R 0.5)
(MAP
(SELECTFONT D 0)
(SETCHAR O 2)
)
)
...
(CHARACTER H 0041
(CHARWD R 0.769)
(CHARHT R 0.709)
(CHARIC R 0.009)
(MAP
(SELECTFONT D 0)
(SETCHAR C A)
)
)
(CHARACTER H 0042
(CHARWD R 0.683)
(CHARHT R 0.684)
(MAP
(SELECTFONT D 0)
(SETCHAR C B)
)
)
...
(COMMENT Begin ombitstreamcyberbitroman01)
(CHARACTER H 0100
(CHARWD R 0.769)
(CHARHT R 0.879)
(CHARIC R 0.009)
(MAP
(SELECTFONT D 1)
(SETCHAR O 0)
)
)
(CHARACTER H 0101
(CHARWD R 0.493)
(CHARHT R 0.657)
(CHARDP R 0.007)
(MAP
(SELECTFONT D 1)
(SETCHAR O 1)
)
)
(CHARACTER H 0102
(CHARWD R 0.769)
(CHARHT R 0.92)
(CHARIC R 0.009)
(MAP
(SELECTFONT D 1)
(SETCHAR O 2)
)
)Dans la maigre documentation que l'on trouve sur Internet, on nous suggère de créer l'en-tête du fichier à la main (sic), puis d'utiliser un programme en C (mkovpd.c, déjà écrit), qui va écrire les données numériques dont on a besoin (d'une part, plein de chiffres en hexadécimal, dans un fichier *.ovp-data, d'autre part, plein de chiffres en octal, dans d'innombrables fichiers *.gil), puis d'utiliser un programme en Python (mkovp.py, lui aussi déjà écrit, mais qui n'est pas portable, car il suppose que la fonte s'appelle ommincho ; d'autre part, il décrète que tous les caractères ont la même hauteur, alors que cette hauteur, donnée par les fichiers *.pl, varie), qui va les fusionner en un fichier *.ovp, que l'on peut finalement convertir en fonte virtuelle *.ovf.
Ça me semble un peu trop compliqué, je vais donc faire cela en une seule fois.
#! perl -w
use strict;
$|++;
use constant TRUE => (0==0);
use constant FALSE => (0==1);
undef $/;
my $font = $ARGV[0];
die "usage $0 font" unless $font;
my $data = "";
my $def = "";
my $head = "(VTITLE '$font' Omega font)
(OFMLEVEL H 1)
(FAMILY om". substr($font, 0, 16) .")
(FACE F MRR)
(SEVENBITSAFEFLAG TRUE)";
my $head_done = FALSE;
# Lecture des 255 fichiers
# $i : numéro de la sous-fonte (il y a des trous
# dans cette manière de compter)
# $n : idem, sans trous
my $n = 0;
my $n_hex = sprintf("%02x", $n);
for(my $i=0; $i<255; $i++){
# On essaye d'ouvrir la sous-fonte
my $i_hex = sprintf("%02x", $i);
unless( open(PL, '<', "$font$i_hex.pl") ){
warn "Cannot open $font$i_hex.pl for reading: $!";
next;
}
my $pl = <PL>;
# Si le fichier est là, on l'indique
$def .= "(MAPFONT D $n
(FONTNAME $font$i_hex)
(FONTAT R 1.0)
(FONTDSIZE R 10.0)
)\n";
# Si c'est la première fois, on termine de construire l'en-tête
unless($head_done){
if( $pl =~ m/^(\(CODINGSCHEME.*?\))/m ){
my $a = "$1\n";
if( $pl =~ m/^(\(DESIGNSIZE.*?\))/m ){
$a .= "$1\n";
if( $pl =~ m/^(\(FONTDIMEN.*?^\s*\))/sm ){
$a .= "$1\n";
$head_done = TRUE;
$head .= $a;
}
}
}
}
$data .= "(COMMENT Begin ommincho$i_hex)\n";
# On regarde les caractères un par un
while( $pl =~ s/^\(CHARACTER ([OC]) ([^\s]+)(.*?)^\s*\)//sm ){
my($type, $value, $parameters) = ($1, $2, $3);
# Quel est le numéro (hexadécimal, unicode) du caractère ?
my $decimal;
if( $type eq "O" ){ $decimal = oct($value) }
else{ $decimal = ord($value) }
my $octal = sprintf("%o", $decimal);
my $hex = $i_hex . sprintf("%02x", $decimal);
$data .= "(CHARACTER H $hex$parameters (MAP
(SELECTFONT D $n_hex)
(SETCHAR $type $value)
)
)\n";
}
$n++;
$n_hex = sprintf("%02x", $n);
}
open(OVP, '>', "$font.ovp") ||
die "Cannot open $font.ovp for writing";
print OVP $head;
print OVP $def;
print OVP $data;
close OVP;
Un fichier d'exemple.
\ocp\TexUTF=inutf8
\InputTranslation currentfile \TexUTF
\documentclass[12pt]{article}
\usepackage[T1]{fontenc}
\DeclareFontFamily{T1}{cyber}{}
\DeclareFontShape{T1}{cyber}{m}{n}{<-> omcyberb}{}
\def\cyber{\fontfamily{cyber}\selectfont}
\begin{document}
{\cyber これはサプル文章です。}
Et même en français...
\end{document}Voici le résultat.
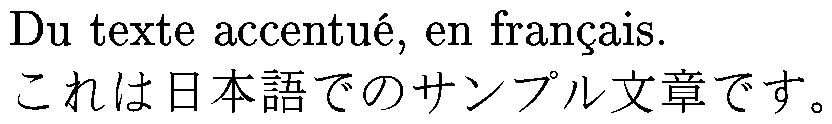
Le nom du fichier doit être de la forme ??cyberb.fd, où les ?? désignent le codage. Je ne sais pas ce que l'on met pour Unicode -- j'ai pris T1 un peu plus haut (mais j'aurais pu mettre « toto »), ça marche très bien, mais ce n'est pas du tout ça.
Dans la suite de ces remarques, j'utiliserai beaucoup le terme OTP (Omega Translation Process) : ce sont des programmes (écrits soit dans un langage un peu rudimentaire (mais portable) qui sera reconnu directement par Omega, soit dans le langage de programmation de son choix) qui permettent de modifier les flux de caractères, par exemple pour passer du codage utilisé pour taper le texte au codage interne utilisé par Omega (c'est le sens des deux premières lignes du fichier d'exemple ci-dessus), par exemple, pour rajouter des informations dans le flux du texte (espaces, autorisations ou interdictions de césure, instructions pour tourner les caractères, furigana, soulignement des mots rejetés par un correcteur orthographique en vue d'une relecture, choix selon le contexte de certaines ligatures), par exemple pour passer du codage interne utilisé par Omega a codage utilisé par une fonte.
La plupart du temps, ces OTP n'existent pas : il faut les écrire soi-même.
Il faudrait expliquer à Omega qu'il ne doit pas tenir compte des espaces dans le texte Japonais (avec CJK, c'est très simple : il suffit d'utiliser l'environement CJK* au lieu de CJK). On doit pouvoir faire cela facilement à l'aide d'un OTP.
Il faudrait expliquer à Omega à quels endroits il a le droit de couper une phrase japonaise : à peu près partout, sauf avant les petits kana (ぁァぃィぅゥぇェぉォぅゥゎヮっッ), le symbole d'allongement des katakana (ー), le point (。), la virgule (、), les parenthèses ou guillemets fermants 」), et après les parenthèses ou guillemets ouvrants 「(. On doit pouvoir faire cela facilement à l'aide d'un OTP.
Si on utilise Omega, il faut regarder quels sont les motifs de césure qu'il connait. Je constate (sur mon installation, vous êtes peut-être plus chanceux) que par défaut, il n'y a que l'anglais et le grec.
This is Omega, Version 3.14159--1.15 (Web2C 7.3.3.1) Copyright (c) 1994--2000 John Plaice and Yannis Haralambous LaTeX2e <1999/12/01> patch level 1 Hyphenation patterns for english, greek, loaded.
En effet, le fichier language.dat utilisé ne contient que
% File : language.dat % Purpose : specify which hypenation patterns to load % while running iniTeX english ushyphen.tex %french frhyphen.tex greek elhyph16.tex
Par ailleurs, je constate que le fichier contenant les motifs de césure français utilise le codage latin1 : c'est peut-être génant. par exemple, il contient des lignes du genre
\catcode"E0=11 \lccode"E0="E0 % \`a
À titre de comparaison, le fichier de césure pour le grec sous Omega contient des lignes du genre
\catcode"0710=12 \lccode"0710=`\á
Je n'ai pas regardé si ça posait réellement des problèmes.
Pour utiliser les fontes TTF Unicode, nous les avons converties en bitmap (en choisissant judicieusement la résolution pour qu'on ne voie pas que ce sont des bitmaps) : mais dans des fichiers PDF, il est tout à fait possible d'utiliser directement des fontes TTF : je ne sais pas comment faire, surtout pour des fontes unicode.
Ce qui précède marche pour les fontes qui contiennent des caractères dans l'ordre d'Unicode, mais il existe des fontes dans lesquelles les caractères sont dans n'importe quel ordre : pour les utiliser, on peut soit mettre les caractères dans l'ordre d'Unicode, soit (en particulier s'il y a des caractères supplémentaires ou des variantes, à utiliser uniquement dans certains contextes) écrire un OTP qui se charge de trouver les bons glyphes, selon le contexte.
Les caractères oe et ß disparaissent quand ils sont tapés directement, mais pas quand ils sont tapés \oe et \ss. Je ne sais pas pourquoi.
On peut aussi écrire verticalement (mais il faut dire à Omega, à l'aide d'un OTP, qu'il faut tourner certains caractères).
Vincent Zoonekynd
<zoonek@math.jussieu.fr>
latest modification on Tue Sep 17 09:19:49 CEST 2002