At work, I have to deal with temporal data on a daily basis (pricing data are almost-regular time series, company or analysts announcements are irregular time series), with huge volumes of data, but I have always had a hard time doing so, because of the lack of a decent, useable time series or temporal database management system. The free software offer is almost void, the commercial software offer is limited to marginal, old, badly documented and/or downright frightening systems (Kx, Caché, FAME, FAST, etc.). What is wrong? What are the needs, the problems? Why aren't they solved? In the meantime, what can we do?
Temporal data are stamped with time; this can be either a point in time or a time interval; and you might want to switch from one point of view to another. Simple operations can become complicated on intervals: for instance, the union of two intervals need no longer be an interval. When time is considered to be discrete, the points in time are called chronons; this defines the granularity of your time model. You might want to use several granularities, e.g., you may want to extract monthly data from a daily database, to extract interpolated daily data from a monthly database for various interpolation algorithms (last-observation-caried forward (locf), linear interpolation, quadratic interpolation) or aggregation algorithms (last value, average, weighted averge, sum, weighted sum). The type of the data influences the choice of the interpolation or aggregation algorithm: for prices, you can interpolate by locf and aggregate by taking the average or last observation; for volumes, you can interpolate by dividing the volume in the desired number of chronons and aggregate by summing the volumes; for returns, you will need to use different aggregattion procedures depending on the dimension on which you are aggregating (you can average ratio returns over stocks, cross-sectionally, i.e., at a given point in time, but you will want to add log-returns to aggregate in the time dimension).
Temporal data can be stamped by several timestamps: the time at which the data was valid (valid time) and the time at which it became publically available and was inserted in the database (transaction time). This allows "point-in-time" recovery, i.e., it allows us to recreate the state of the database at a given point in time (useful to identify the source of erroneous data), but also, more importantly, helps us avoid a look-ahead bias: for instance, accounting data valid at the end of a fiscal year are only available a few months later -- backtests should not assume the data was available earlier.
You might also want non-linear time, for instance to track changes made to the data by several people, as in the branches of a version control system -- but expect the system to become unmanageable if you actually use such a facility.
To have full point-in-time recovery, you also have to track the changes made to the schema of the database.
Some timestamps have to be treated specially: missing values (time stamps that should be there but, for some reason, are missing); missing values with some information, such as "some time in the future", that will eventually be updated; infinity (forever); now. "Now" is actually the trickiest timestamp: its meaning changes -- in particular, if you need to use it to express database constraints, constraints that were satisfied can suddenly become breached, without any change in the database, just because time passed.
Since their semantics are different, those four special time stamps should not be confused.
Some people might want the database to be able to store infinite events, such as "every Tuesday, until the end of time" and suggest to consider temporal databases as constraint databases or "temporal deductive databases" that can be described in Datalog (a trimmed-down version of Prolog) -- I am not convinced this is a good idea if you have a lot of data to store.
In the same vein, some people might want to store imprecise data, such as "one day in the first week of July" -- here again, this can be done using logic (or logic programming languages) to describe the data.
As a result, the concern of storing and retrieving large amounts of data (as opposed to extracting a single simple answer from the data) is largely ignored. To stress that they consider the problem unimportant and boring, researchers tend to distinguish between time-series databases (with huge datasets) from temporal databases.
Real-time systems (or, at least, real-time problems) are all around us: the computations we run are no longer triggeres by a time stamp ("every morning at 6:00") but by the arrival of the data ("as soon as the data is updated" -- "as often as the data is updated").
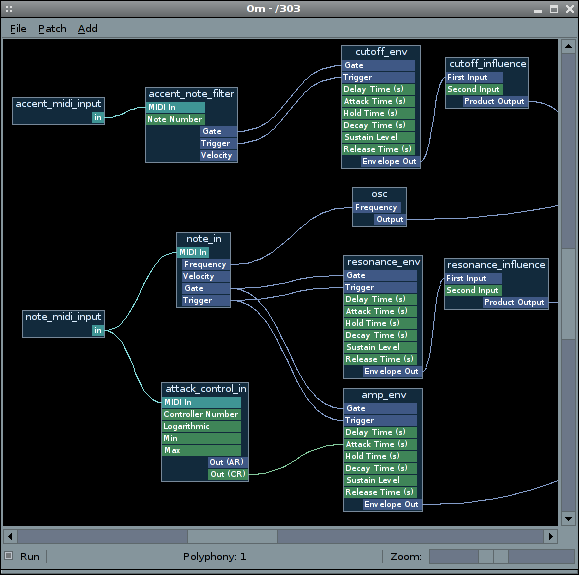
Real-time systems are usually flow-processing engines: the computations can be represented as a directed graph, with the data coming in from one side and the results coming out from the other. They are remarkably absent from the free software landscape, except in the music arena (Pure Data, Ingen (formerly Om-Synth), Csound, etc.).
I have never intensively used such a system, but underneath a very appealing GUI varnish, the nature of the computations you can put in the nodes is usually very limiting.
Although SQL is fine for simple queries, using it for complex queries can be challenging: I tend to cut my code into small chunks and create a temporary table for each of them; other people use views instead, which is cleaner, more efficient, but more difficult to debug; some people (most SQL books, actually) even try to put everything into a single mammoth query.
Is there any progress in this area? Is there any new query language emerging?
Sadly, researchers spend a lot of time debating which logic is the best query language: first order logic, temporal logic, etc. -- there are many of them and comparing how expressive they are seems to be very time consuming.
Tutorial D is perhaps the most "useable" (even though there is no implemention of it, nor even any plan to implement it): it is just a formalization of relational algrbra used by C.J. Date in his books. One of the features I appreciate is the separation of aggregate operations (average, maximum, etc., with a GROUP BY clause) into two steps: first grouping the data, then applying the aggregate function.
The expression "data mining" has several derogatory meanings: many people use it as a synonym of "data snooping", i.e., extraction of irrelevant information from large amounts of data; some people (most books about "data mining" and databases) use it to refer to push-button regression-like algorithms.
But for time series databases, again, the domain seems to be dying -- at least one active researcher remains, though:
http://www.cs.ucr.edu/~eamonn/
Also check the books:
http://www-stat.stanford.edu/~tibs/ElemStatLearn/ http://www.amazon.com/Databases-Machine-Perception-Artificial-Intelligence/dp/9812382909
The SQL standard used to contain a section entitled "SQL/Temporal" that extended SQL to allow to easily formulate temporal queries (it failed to solve the "NOW" problem, though).
This section was abandonned due to lack of interest and/or time.
Another solution is to extend the SQL language yourself and write a translator from your language to standard SQL, to leverage off-the-shelf SQL databases.
For data- and computation-intensive tasks, the computations should be performed as close to the database as possible -- ideally, in the database. SQL only allows this to some extent: PostgreSQL allows you to write functions in R (or Perl, C, etc.); Oracle's window functions (LEAD, LAG) can efficiently compute some time series quantities (moving averages, returns, etc.) but this is either limited to small amounts of data or very rigid: we do not have a close integration between data and code.
Some software or data vendors claim to provide a solution. Vision (the technology was bought by Factset five or six years ago and is now sold, with data, under the name "FAST") is a Smalltalk interpreter with an embedded time series database: this is a real programming language (Smalltalk was popular in the 1980s but is now getting more widespread, thanks to the Squeak interpreter, Etoys in the OLPC (one laptop per child) project, the Seaside application server (check http://www.dabbledb.com for an example), etc.) which can access objects from the database transparently, as if they were local variables. Vision also includes a version control system (with no branching, though): since the schema is the code, it means that it also tracks schema changes.
Is this the answer to our time series database problems? From a theoretical point of view, yes, indeniably -- but practically, we could not have stranded farther away from our goal: the performance is awful, the language is not documented (they do not say "this is smalltalk, you can learn it from any Smalltalk or Squeak book" but "this is Vision, a proprietary technology: we managed to dig up the following old, superficial training material"), the data is not there (when looking for the price of a stock, you can find a dozen slots called "price", most of which are empty or only contain obsolete data) -- even worse, the schema of the database is not documented (this is not a joke -- and when you have to use such a system, it is far from funny). Last but not least, in the companies using FAST, only people in the data center actually use the system: this is often the best way to gauge the (re)usability of a piece of software -- check if it is (re)used...
FAME, Kx, Caché might be similar (but they are empty time series databases), but I have never used them.
The safest, quickest bet is probably to use SQL directly: for time-stamped data, your tables would have (identifier, date) as a primary key, for interval-stamped events, it would be (identifier, start_date, end_date) with end_date set to 9999-12-31 for open-ended intervals; you would have one table per data source and data frequency. Such tables can be joined as follows
SELECT X.id,
MAX(X.start_date, Y.start_date) AS start_date,
MIN(X.end_date, Y.end_date) AS end_date,
X.data_1, Y.data_2
FROM X, Y
WHERE MAX(X.start_date, Y.start_date) <= MIN(X.end_date, Y.end_date);Depending on your needs, you might prefer a more complicated design, such as a table containing current data and a table with historic data (this avoids the 9999-12-31 kludge); or a table with current data and a log table (containing the changes to the data).
Even if you think you do not need bitemporality, I suggest adding an auto-populated column with the data of time of the latest modification of each row: it is invaluable when you track down a data problem. Some people also add the name of the person or process who modified the row.
Even if you use a non-SQL system, it should have an SQL interface, with which most users are already familiar -- for instance, Monet (a free, in-memory, column database) provides several interfaces (SQL, XQuery, etc. -- I checked it six months ago, looking for an XQuery processing engine to ditch XSLT but, sadly, I could not get the XQuery part to work...).
Even with an SQL system, you might want to abstract the data structure from the user, to avoid too strong a reliance on a given schema, which will eventually change: either by providing SQL views (in some companies, end-users are not even allowed to access the data directly from the SQL tables, they have to use views instead -- each table typically has its own, trivial view) or by providing an API, completely eschewing SQL (this can prove useful when you want to add data that do not easily fit in an SQL database, such as years of tick data).
You will not only want to store the data, but also to compute with it. Computations on large datasets are usually best done as close from the data as possible: in some situations, it can be done in SQL (I already mentionned Oracle's window functions and PostgreSQL's stored procedures in R). If this is not sufficient, or if you are more versed in R than SQL, you can always download all the data you need into memory (memory is cheap -- I hope you are not stuck on Windows, who restricts its use). The data I work with is often stored in tables whose primary keys are (identifier, date) and I convert those tables into lists of matrices (one matrix per variable, one row per identifier, one column per date -- I put the dates in columns, because I am used to plotting time on the horizontal axis) using functions such as
"DataFrameToList" <-
function (d, id_name=NULL, date_name=NULL, verbose=FALSE, convert_dates=TRUE) {
if (verbose) {
dcat <- cat
} else {
dcat <- function (...) {}
}
dcat(" DataFrameToList: Checking the arguments\n")
stopifnot( is.data.frame(d),
dim(d)[2] > 2 )
if (is.null(id_name) & is.null(date_name)) {
dcat(" DataFrameToList: Guessing the name of the Id and Date columns\n")
stopifnot(any( c("id", "Id",
"Sedol", "sedol", "SEDOL",
"cusip", "CUSIP", "Cusip",
"ticker", "Ticker", "TICKER") %in% names(d)[1:2] ))
stopifnot(any( c("Date", "date") %in% names(d)[1:2] ))
if ( names(d)[1] %in% c("Date", "date") ){
names(d)[1] <- "Date"
names(d)[2] <- "Id"
dcat(" DataFrameToList: Switching columns 1 and 2\n")
gc()
d <- d[, c(2,1,3:dim(d)[2])]
gc()
dcat(" DataFrameToList: Done\n")
} else {
names(d)[1] <- "Id"
names(d)[2] <- "Date"
}
} else if ( ! is.null(id_name) & ! is.null(date_name) ) {
stopifnot( id_name %in% names(d),
date_name %in% names(d),
id_name != date_name )
dcat(" DataFrameToList: gc()\n")
gc()
dcat(" DataFrameToList: Making sure the Id and Date columns are the fist two ones\n")
d <- d[, c(id_name, date_name,
setdiff(names(d), c(id_name, date_name)))]
dcat(" DataFrameToList: gc()\n")
gc()
dcat(" DataFrameToList: Done\n")
names(d)[1:2] <- c("Id", "Date")
} else {
stop("Both id_name and date_name should be NULL or non-NULL.")
}
dcat(" DataFrameToList: Checking the Id and Date columns\n")
stopifnot( names(d) [1] == "Id" )
stopifnot( names(d) [2] == "Date" )
stopifnot( length(d) > 2 )
dcat(" DataFrameToList: Looking for missing dates or identifiers\n")
stopifnot(all(!is.na( d$Id )))
stopifnot(all(!is.na( d$Date )))
dcat(" DataFrameToList: gc()\n")
gc()
dcat(" DataFrameToList: Converting the date column to dates\n")
if (convert_dates) {
number_of_dates <- length(unique(d$Date))
d$Date <- as.Date(d$Date)
if (number_of_dates != length(unique(d$Date))) {
stop("Some information was lost while converting to dates: try convert_dates=FALSE")
}
} else {
dcat(" Skipped\n")
}
d$Date <- as.character(d$Date)
stopifnot(all(!is.na( d$Date )))
stopifnot(d$Date != "")
dcat(" DataFrameToList: gc()\n")
gc()
dcat(" DataFrameToList: Checking for duplicate entries\n")
stopifnot(all( table(d$Date, d$Id) <= 1 ))
dcat(" DataFrameToList: Filling in missing values\n")
a <- table(d$Id, d$Date) == 0
if (any(a)) {
dcat(" DataFrameToList: Missing (id,date) pairs\n")
dd <- data.frame(
Id = rownames(a)[row(a)[a]],
Date = colnames(a)[col(a)[a]]
)
dcat(" DataFrameToList: (id,date,NA,NA,...) rows\n")
dd <- cbind(dd, matrix(NA, nr=sum(a), nc=dim(d)[2]-2))
names(dd) <- names(d)
dcat(" DataFrameToList: Appending this to the initial data.frame\n")
d <- rbind(d, as.data.frame(dd))
dcat(" DataFrameToList: gc()\n")
gc()
}
dcat(" DataFrameToList: Checking for consistency\n")
stopifnot(all( table(d$Date, d$Id) <= 1 ))
stopifnot(all( table(d$Date, d$Id) == 1 ))
dcat(" DataFrameToList: row and column names\n")
ids <- sort( unique(d$Id) )
dates <- sort( as.character(unique(d$Date)) )
# The order in which the elements are, in order to put them direcly into
# a matrix.
dcat(" DataFrameToList: computing the order of the elements\n")
o <- order(d$Date, d$Id)
dcat(" DataFrameToList: main loop\n")
l <- list()
for (i in 1:(length(d)-2)) {
dcat(" ", i+2, "/", length(d), ": ", names(d)[i+2], "\n", sep="")
r <- matrix(d[o,2+i], nr=length(ids), nc=length(dates))
colnames(r) <- dates
rownames(r) <- ids
names(dimnames(r)) <- c("id", "date")
l[[ names(d)[2+i] ]] <- r
}
return(l)
}
"ListToDataFrame" <-
function (l) {
stopifnot(is.list(l))
if (length(l)==0)
return(NULL)
for (i in 1:length(l)) {
stopifnot(is.matrix(l[[i]]))
stopifnot(colnames(l[[1]]) == colnames(l[[i]]))
stopifnot(rownames(l[[1]]) == rownames(l[[i]]))
}
data.frame(
Id = rownames(l[[1]]) [ row(l[[1]]) ],
Date = as.Date(colnames(l[[1]])) [ col(l[[1]]) ],
as.data.frame( lapply(l, as.vector) )
)
}
"LAG" <-
function (x,k=1) {
if (is.vector(x)) {
dn <- names(x)
if (k > 0) {
x <- c( rep(NA,k), x )[1:length(x)]
} else if (k<0) {
k <- -k
x <- c( x[ -(1:k) ], rep(NA, k) )
}
names(x) <- dn
} else {
dn <- dimnames(x)
if (k>0) {
x <- cbind( matrix(NA, nr=dim(x)[1], nc=k), x ) [,1:dim(x)[2]]
} else if (k<0) {
k <- -k
x <- cbind( x[, -(1:k)], matrix(NA, nr=dim(x)[1], nc=k) )
}
dimnames(x) <- dn
}
x
}
"MA" <-
function (x, k) {
if (is.vector(x)) {
dn <- names(x)
if (length(x) >= k) {
x <- filter(x, rep(1/k,k), sides=1)
} else {
x <- rep(NA, length(x))
}
x <- as.vector(x)
names(x) <- dn
} else {
dn <- dimnames(x)
if (dim(x)[2] >= k) {
x <- t(apply(x,1,filter, rep(1/k,k), sides=1))
} else {
x <- matrix(NA, nr=nrow(x), nc=ncol(x))
}
dimnames(x) <- dn
}
x
}
"moving" <-
function (x,FUN, width, by=1, ...) {
was_vector <- FALSE
if (is.vector(x)) {
was_vector <- TRUE
y <- matrix(x, nr=1)
colnames(y) <- names(x)
x <- y
rm(y)
}
n <- dim(x)[2]
stopifnot(width <= n)
res <- matrix(NA, nc=n, nr=dim(x)[1])
colnames(res) <- colnames(x)
rownames(res) <- rownames(x)
for (k in seq(from=width, to=n, by=by)) {
res[,k] <- apply(x[,(k-width+1):k,drop=FALSE], 1, FUN, ...)
}
if (was_vector) {
res <- as.vector(res)
}
res
}Stored procedures in R:
http://www.joeconway.com/plr/
A column-database with several interfaces (SQL, XQuery):
http://monetdb.cwi.nl/
Time in SQL and the relational model:
C.J. Date et al., Temporal data and the relational model (2003) R.T. Snodgras, Developing time-oriented database applications in SQL (2000) Out of print, but available on the author's web page: http://www.cs.arizona.edu/people/rts/tdbbook.pdf
Academic articles on time series databases or temporal databases:
http://citeseer.ist.psu.edu/cis?q=time+series+database&cs=1 http://citeseer.ist.psu.edu/cis?q=temporal+database&cs=1
Time series databases in finance:
D. Shasha, Time series in finance: the array database approach http://cs.nyu.edu/shasha/papers/jagtalk.html
Data flow languages:
Advanced Programming Language Design, R. Finkel (1995)
Data flow programming and time series:
G. Zumbach and A. Trapletti, Orla, a data flow programming system for very large time series (Olsen) http://citeseer.ist.psu.edu/508369.html
Data flow and computer music:
http://wiki.drobilla.net/Ingen http://en.wikipedia.org/wiki/Pure_Data
For more information about computer music and the sometimes wird languages behind it:
Notes from the Metalevel http://www.amazon.com/Notes-Metalevel-Introduction-Computer-Composition/dp/9026519753 Linux Audio Conference proceedings http://www.kgw.tu-berlin.de/~lac2007/proceedings.shtml http://lac.zkm.de/2006/proceedings.shtml http://lac.zkm.de/2005/proceedings.shtml Linux Audio Users mailing list http://lalists.stanford.edu/lau/
A few commercial data flow systems (or "event-engines"):
http://www.streambase.com/ http://www.progress.com/ http://www.coral8.com/ http://www.aleri.com/
The Smalltalk revival (beware of Squeak: although it is becoming more widespread, it still does not seem very robust -- it particular, its claims to be "portable" look fishy, to say the least: it does not cleanly compile on 64-bit architectures (lots of "cast from pointer to integer of different size" warnings eventually leading to a segmentation fault)):
http://www.squeakbyexample.org/ http://wiki.laptop.org/go/The_Children's_Machine http://www.seaside.st/ http://www.dabbledb.com
posted at: 19:17 | path: /Finance | permanent link to this entry
